
Photo by RODNAE Productions from Pexels
This is part of my series on learning to build an End-to-End Analytics Platform project.
TLDR; I made improvements to the Infrastructure as Code from the previous post by following best practices and promoting code reuse. Continued with parameters, but extended the code with scopes, modules, variables, functions, operators, and outputs. There is a list of Bicep best practices that is worth looking into.
Divide and conquer
We can use modules to group a set of one or more resources to be deployed together. We can reuse modules for better readability and reuse. They basically get converted to nested ARM templates from what I understand.
The first part that I want to move int a module is the data lake storage account and resolve dependencies. When that’s done, repeat the process for the other resources that we want to deploy.
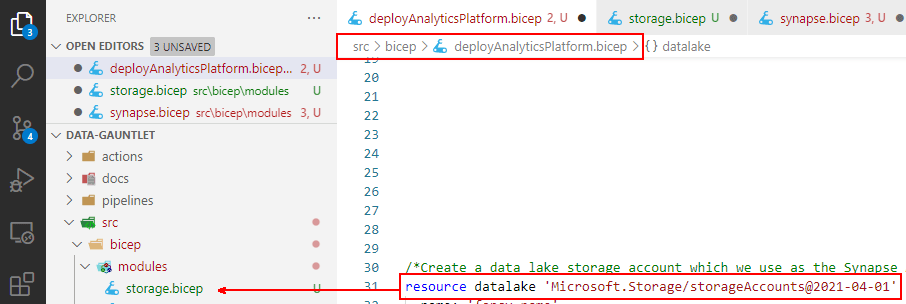
Next up, update modules to use parameters and variables where possible to avoid hard coded values. We should be in a position where the module is bit of code that can be called with a set or parameters. Note that when the resources are in the same file, you can reference them directly. An example from my previous post was were I reference the datalake resource.

A module only exposes parameters and outputs to other Bicep files. When we move the data lake resource creation to a module, we need to leverage outputs which can then be passed between modules. The idea is to call a module -> deploy the resource -> output important things -> pass those things to another module as input parameters. So, the same property I referenced before now becomes an output in the module of the storage account:

Output variables can now be used in the main script as inputs to another module, etc. We just reference them using the module.output syntax.

We use operators in our deployments for things like conditional deployments.

Expanding on the use of parameters and variables, functions are a great way to drive flexibility and reuse into your deployments. Getting runtime details, resource references, resource information, arrays, dates, and more. Just remember most work at all scopes, some don’t. When they don’t you will probably figure that out with errors. One way to use them is to inherit the resource group location during resource deployment. In our case, setting variables with the resource group location, appending a deterministic hash string suffix for the storage account name from the resource group, or even enforcing lower case of names then using the variables for deployment.

FYI, the weird looking string notation ‘${var}‘… that’s call ‘string interpolation‘. Pretty simple compared to other ways I’ve had to write parameterised strings before with all kinds of place holders, parameters, and functions. I like!
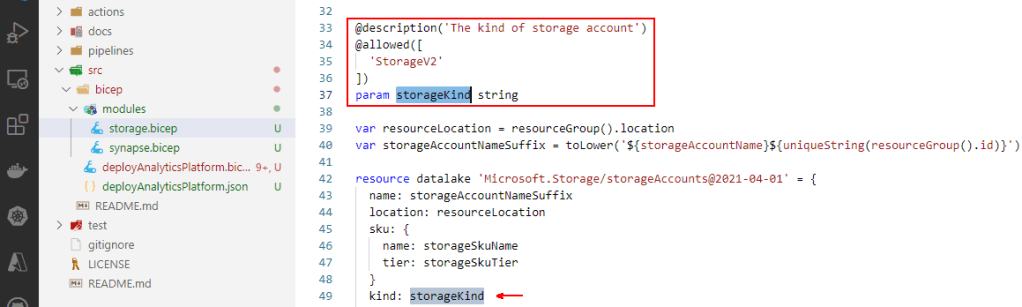
As a good practice we use parameter decorators to control parameter constraints or metadata. Things like allowed values, lengths, secure strings, etc.
What we do next in our main deployment file is to change the scope. That way we can deploy at the subscription level which let’s us create resource groups in bicep instead of the Azure CLI which we did in the previous post.
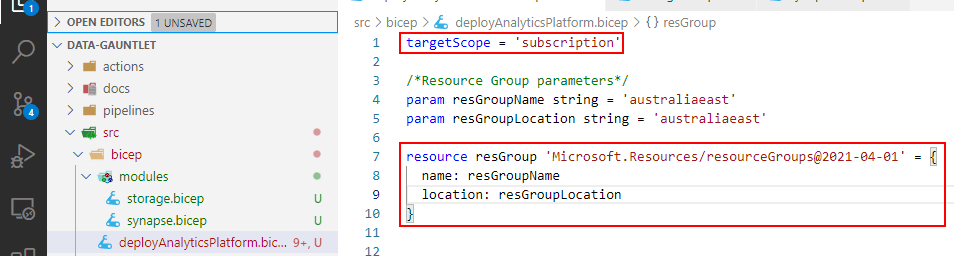
Note: It’s preferred in most cases to put all parameters/variables at the top of the file.
One other point of interest is that when we change the scope, our module to deploy resources error because they can’t be deployed at the subscription level only the resource group level. Make sense. So we need to change their scope in deployment.

Polishing up the current solution with these practices was good learning. I continued with the approach across all modules and files. Then ran a few tests to make sure the resources deploy as expected.
That covers it off for this post. What I think we will do next is work on setting up a CI/CD pipeline in GitHub to build and deploy these resources into Azure.
🐜
