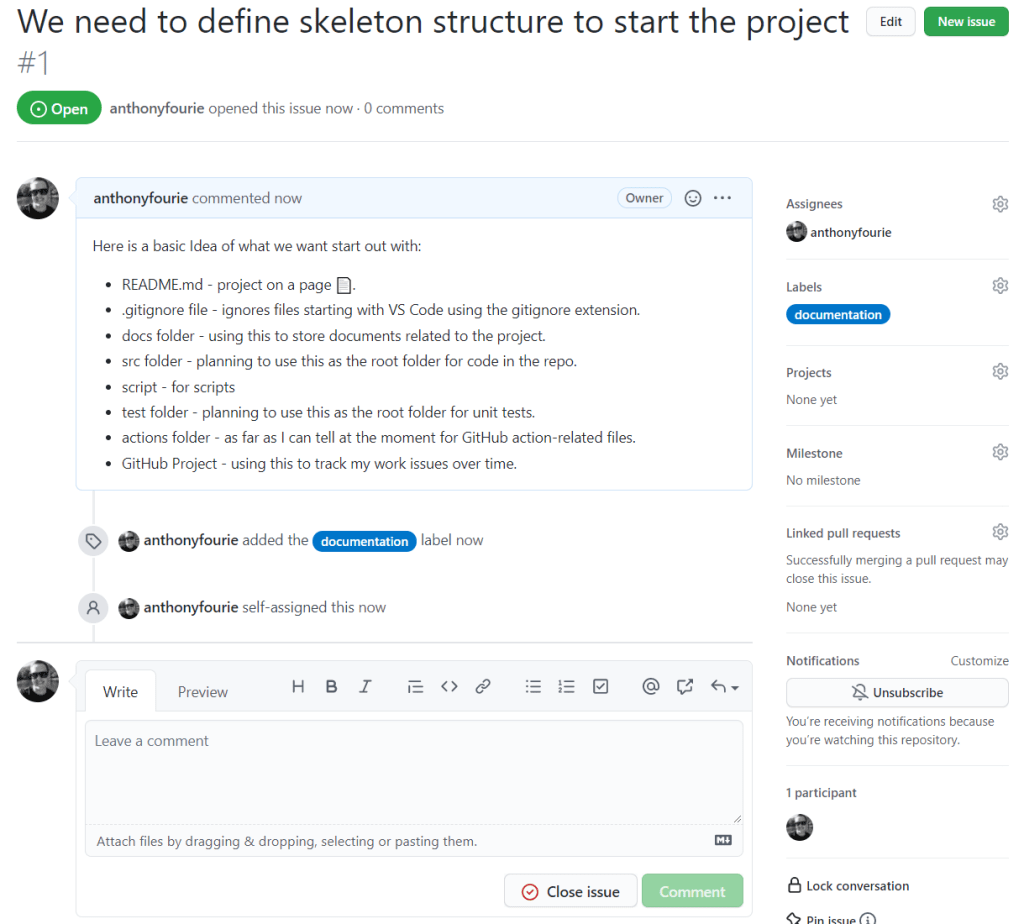
This is part of my series on learning to build an End-to-End Analytics Platform project.
TLDR; This post we got started with GitHub Actions. Test drove Excalidraw for diagraming. While building the workflow learnt Yaml in y minutes. Started with a simple starter workflow. Worked through deploying Bicep files by using GitHub Actions.
Automate construction 🚧
Now that we have the code set up and we can deploy it manually it’s time to autobot automate. We are going to use GitHub Actions for Azure to work on building our Continuous Integration/Continuous Deployment pipeline.
What we are looking to create is a workflow to automate tasks. Actions are event-driven. An example is “Run my testing workflow when some creates a pull request.”. What makes up a workflow? Queue Intro to GitHub Actions. To start off the thinking I get to test out a pretty fantastic open-source whiteboard tool, with tons of potential, called Excalidraw. *Inner voice screaming… “Excalidraw, I choose you!”* ⚔️
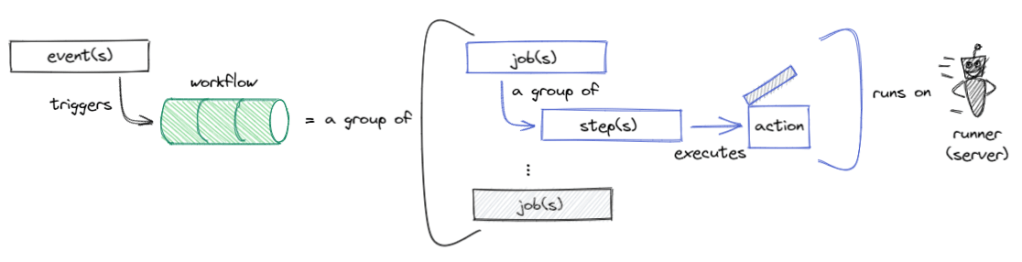
- A workflow is an automated procedure that you add to your repository.
- A job is a set of steps trigger by event/webhook or scheduled that execute on the same runner.
- A step is an individual task that can run commands in a job.
- Actions are standalone commands that are combined into steps to create a job.
- A runner is a server that has the GitHub Actions runner application installed.
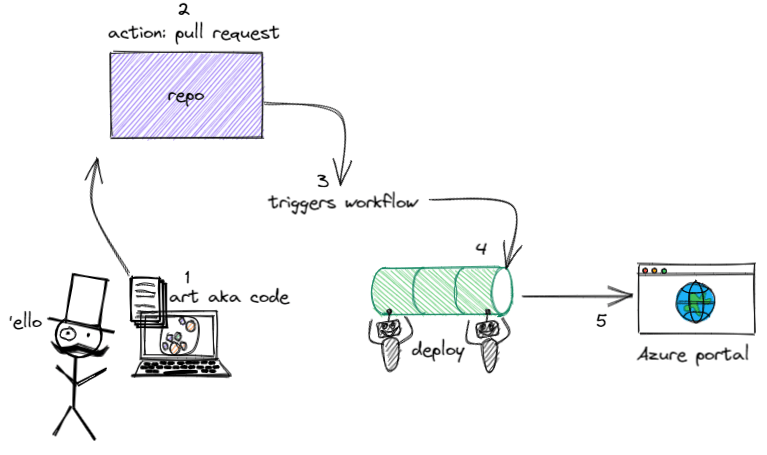
Now that we know some basics, let’s dive in and give it a go. Here is the plan for what we want to achieve with an accompanying artistic depiction:
- Develop some code, commit to our branch, push the changes
- Then complete a pull request and merge the changes
- The GitHub action triggers the workflow
- The workflow runs our jobs and steps to deploy the resources
- Validate the resources got deployed to Azure
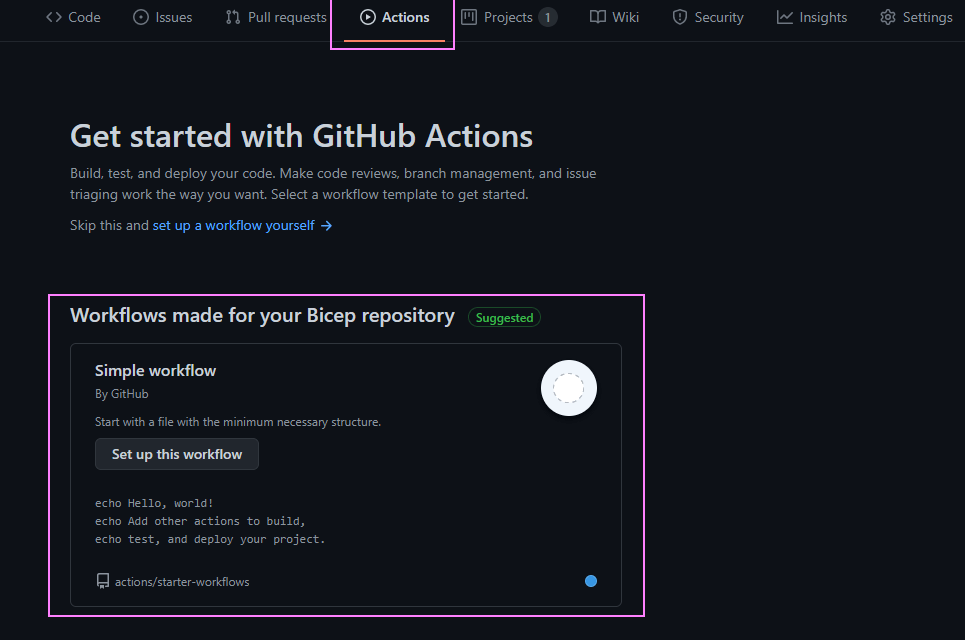
Let’s create our first GitHub Actions workflow. Navigate to the ‘Actions‘ tab in our repo. We get a few workflow templates we can use. Let’s use the ‘Simple workflow‘ by using the ‘Set up this workflow‘ button.
GitHub actions use YAML syntax for defining events, jobs, and steps. When we created the workflow, GitHub added a new .github/workflows directory to our repo. It created a new .yml file which I renamed to build.yml in that directory. For those of us that don’t speak YAML fluently, we can learn x(yaml) in y minutes 🧪.
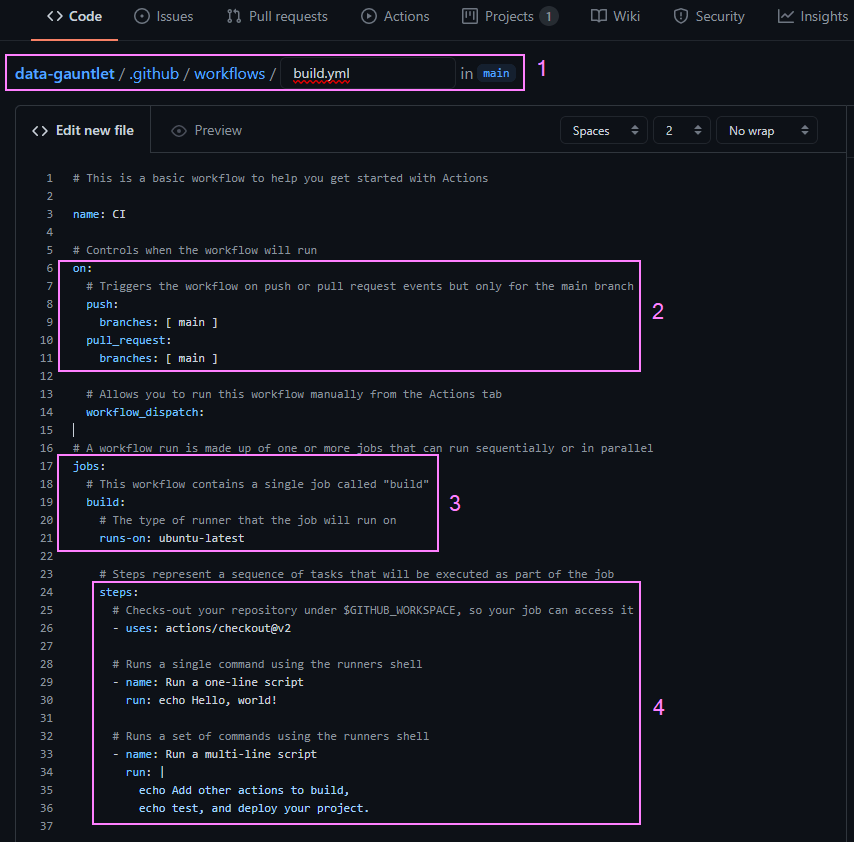
A brief summary of what is going on here:
- Our new YAML file and path was added to our repo
- We can see our workflow is triggered on a push or pull request actions to our main branch
- We have one job that runs on a Ubuntu runner server
- We have three demo steps
- Uses a packaged action from https://github.com/actions/ called checkout to checkout our repo
- Runs a single line script in the runners shell
- Runs a multi-line script in the runners shell
That’s a good enough starter template. From this point on, for brevity, I followed the documentation to deploy Bicep files by using GitHub Actions. That covers setting a deployment service principal (My choice, Windows Terminal Prettified), configuring GitHub secrets, and the sample workflow to deploy Bicep files to Azure. Once that is all set up, we have a workflow that looks like this:
Note: Though not the recommended practice. I adjusted the scope of my service principal to a subscription level. For my testing I would like GitHub Actions to create resource groups using my Bicep file definitions not the CLI. So my command was a little different:
az ad sp create-for-rbac --name {myApp} --role contributor --scopes /subscriptions/{subscription-id} --sdk-authAfter reading the Azure/arm-deploy documentation and the exampleGuide

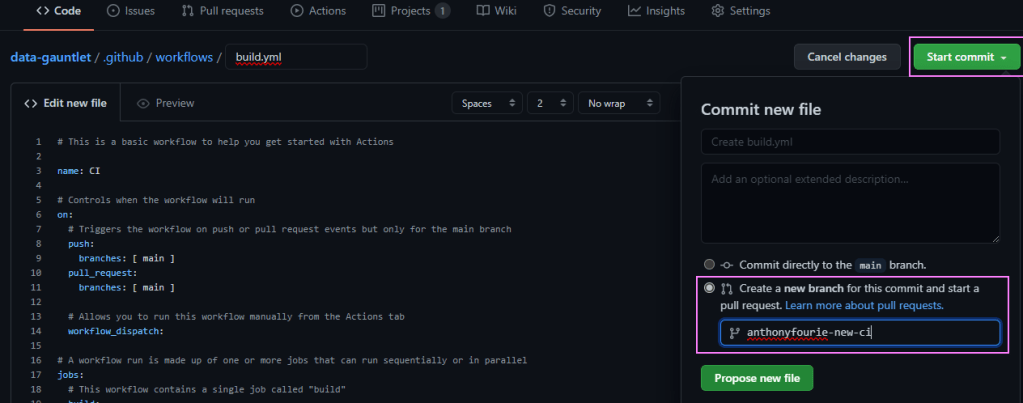
To commit our changes, just use the ‘Start commit’ button in the top right corner. I created a new branch from here for the change, then just finished the pull request from there, merging our changes to the main branch.
Remember our triggers? On pull_request to main? That kicks off our pipeline 😎
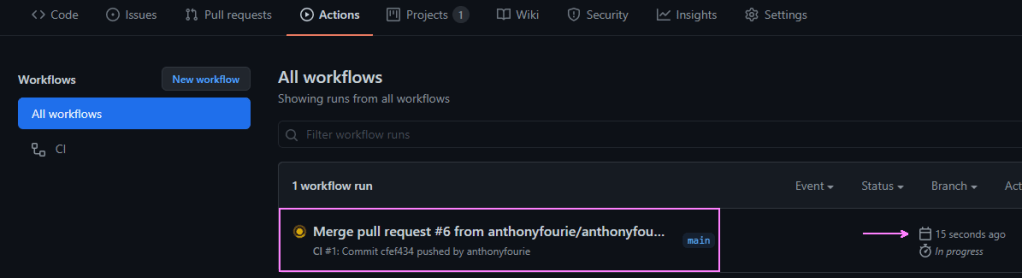
Full disclosure: It failed. lol.
- I got an error “missing ‘region’ parameter” for the Azure/arm-deploy action
- I adjusted the file path for the ‘deployAnalyticsPlatform.bicep’ file from root to the src/bicep directory.
- I also modified the trigger to only fire when a push is done to the main branch. That prevents us running the pipeline twice, once for the pull request, then again when the merge us run.
So we learn 😉

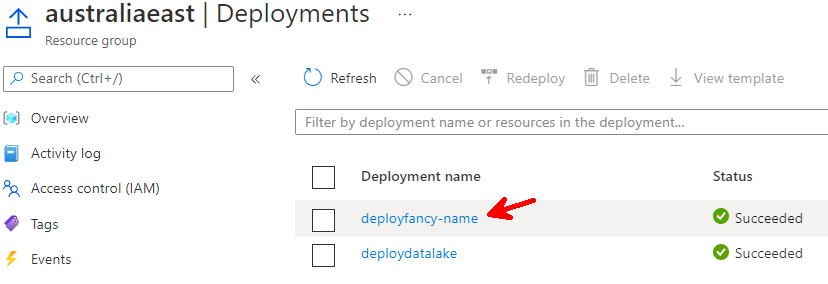
Quick update to the code. Run through the GitHub flow again and we are back in business. When we navigate into the Action we can see a bunch of information. Why the workflow was triggered. What’s the status. Which jobs are running.
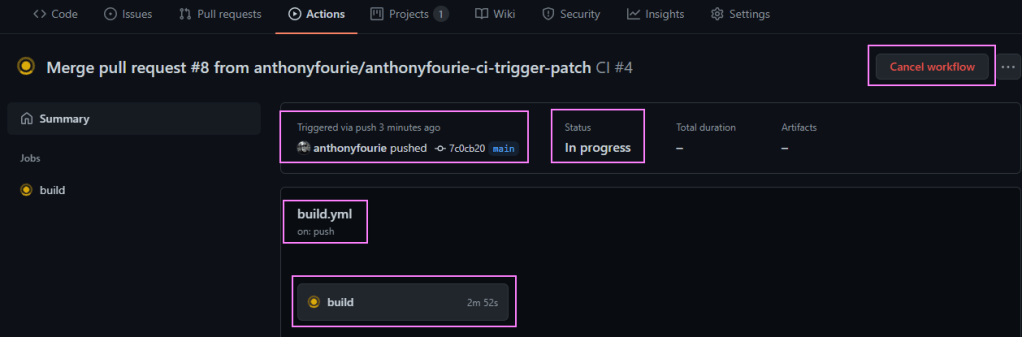
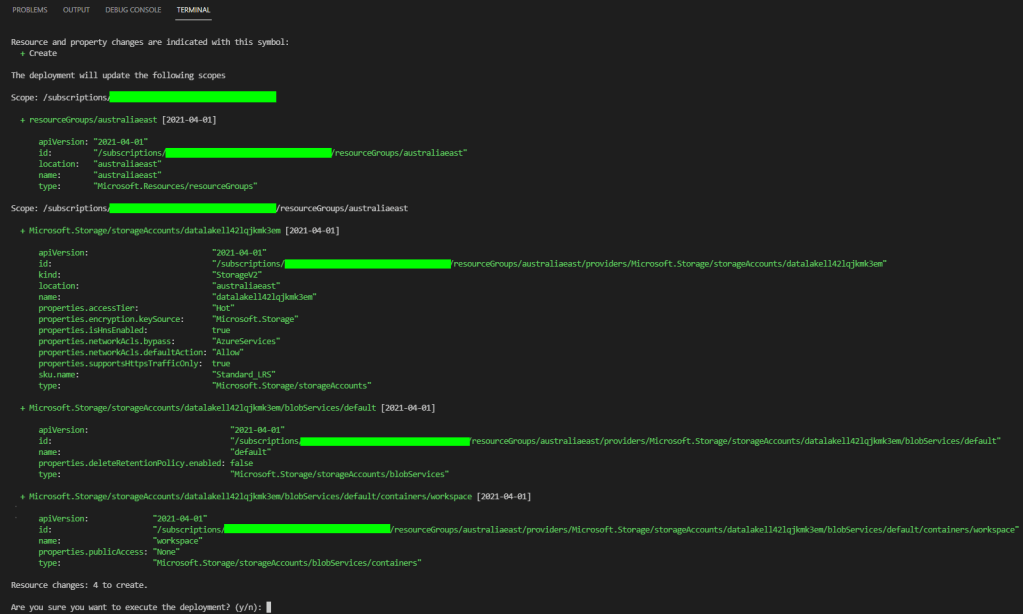
When we click on the job, we can drill into the runner logs as well. This helps a bunch in debugging workflows. An example, is that we have a property for the storage account which is read-only:
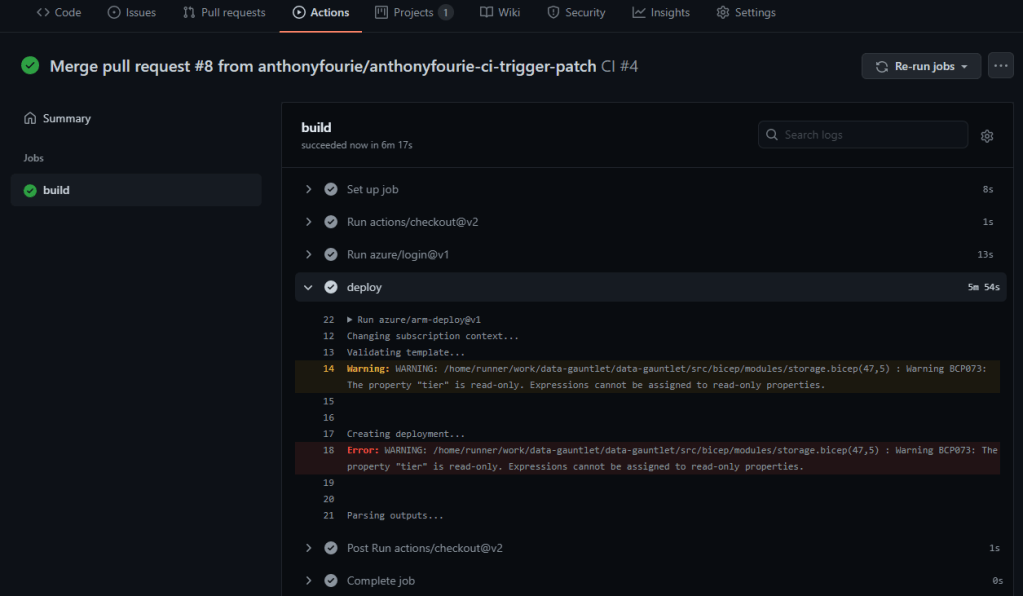
The deployment succeeded though which I think is great progress!
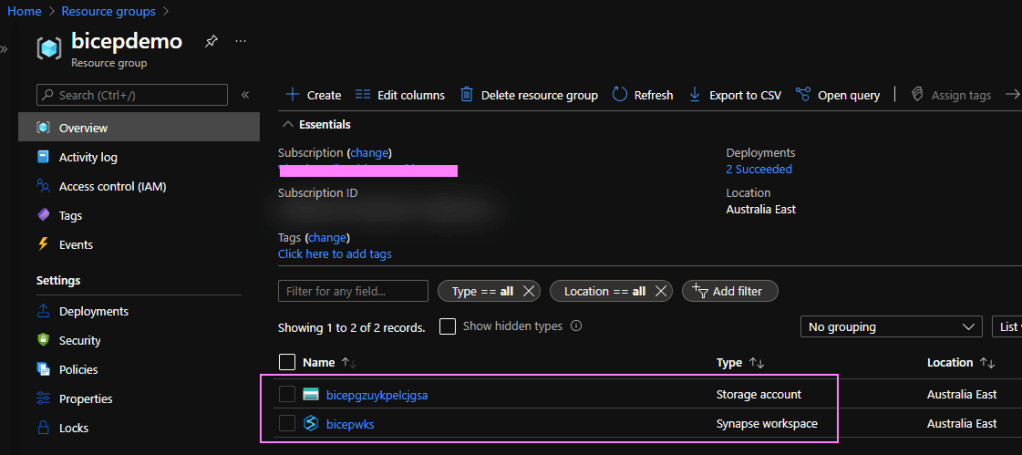
That’s it! All done. Explored GitHub actions. Created service principals and GitHub secrets. Learnt some YAML. Broke and fixed our workflows. Then successfully deployed resources from Bicep code.
🐜
P.S. A really simple video that also helped me rapidly establish some key points quickly was: GitHub Actions Tutorial – Basic Concepts and CI/CD Pipeline with Docker