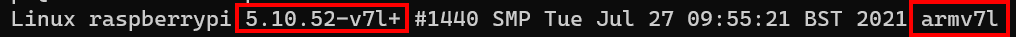The plan is to be able to use computer vision to detect objects or events, send events based on detection, process the event, then send an event or command back down to the device to perform an action. We’ll start with local development then explore cloud in future posts. Yup, the end-to-end analytics platform project is growing in scope, that’s okay.
Lights, camera, action! 🎥
Now to detect, capture, and even track objects with a computer vision solution we need something that can ‘see’ and ‘move’. The Pimoroni has a pan-tilt hat to ‘move’ with servos to pan (x-axis) and tilt (y-axis) the mounted camera. We also have a NoIR Pi Camera to help ‘see’. NoIR means NoInfrared. Why not the normal one? This one basically has night vision. Case closed.
Compute, uh, vision? 😁
After removing the SenseHAT we used before, which we can see in the background. We can use the Pimoroni guide for assembly to get the new hat set up. One thing we don’t have is the Neopixel stick (light) which we don’t need.
Interesting point 💡
Pan-Tilt HAT is a two-channel servo driver designed to control a tiny servo-powered Pan/Tilt assembly. - Pimoroni pan-tilt hat Github repoWhat's a servo? A servomotor (or servo motor) is a rotary actuator or linear actuator that allows for precise control of angular or linear position, velocity and acceleration.[1] It consists of a suitable motor coupled to a sensor for position feedback. It also requires a relatively sophisticated controller, often a dedicated module designed specifically for use with servomotors - Wikipedia
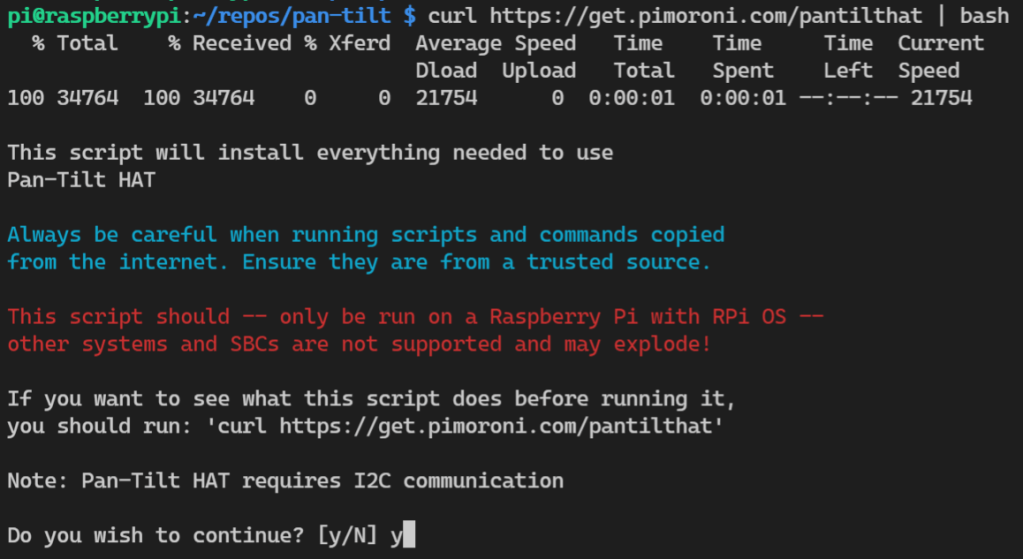
We’re focused on getting the pan-tilt working, not the camera. We’ll set up the camera when we do the object detection, image capture, etc. The kind maintainers of the Pimoroni pan-tilt hat Github repo have graciously bestowed upon us a curl command to install everything we need.
curl https://get.pimoroni.com/pantilthat | bash
Wait… “may explode”? 💥
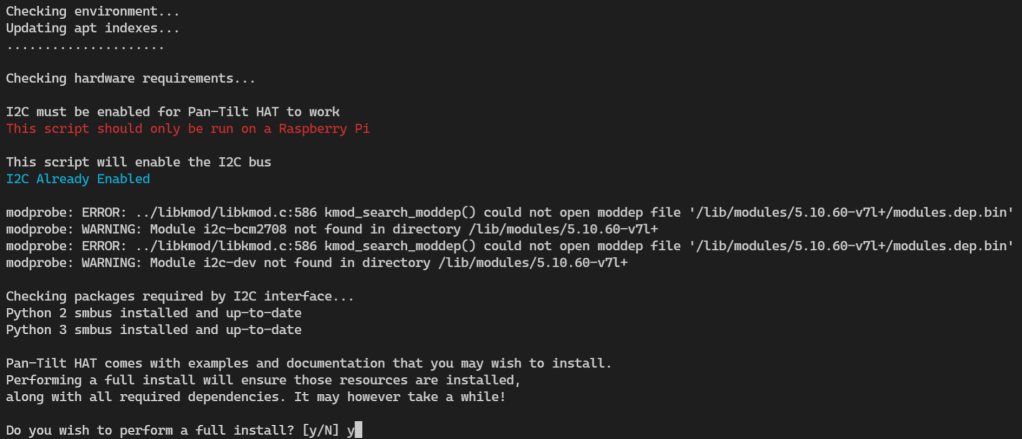
Because we already enabled the I2C using the raspi-config tool, we can see the setup noticed that and printed out ‘I2C Already Enabled’.
Fully prepared 👍
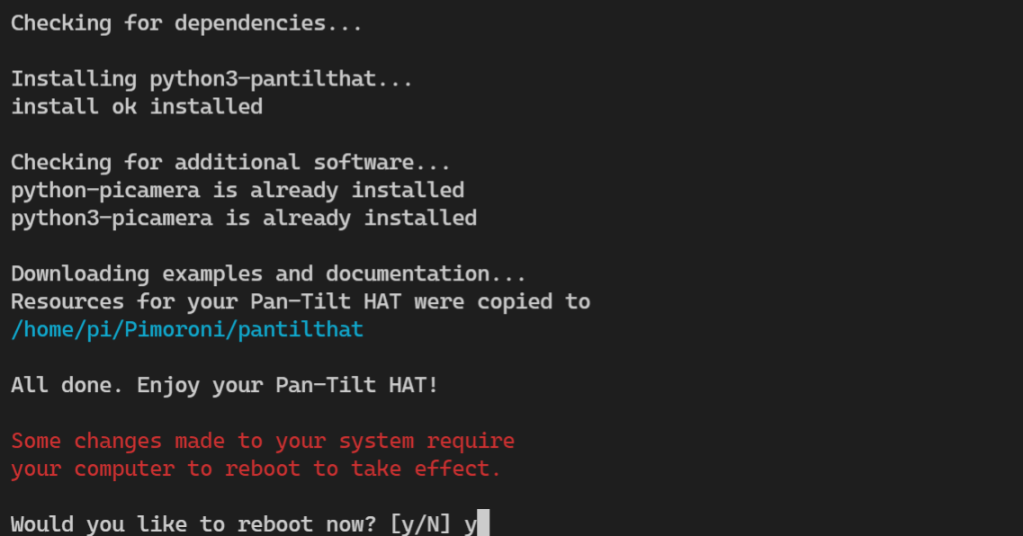
We’re going to opt for the full install so that we can grab the examples and docs for future. You know, just in case 😏.
Joyful exclamation ❗
Installation done, let’s turn the key 🗝️ and see if this beauty starts.
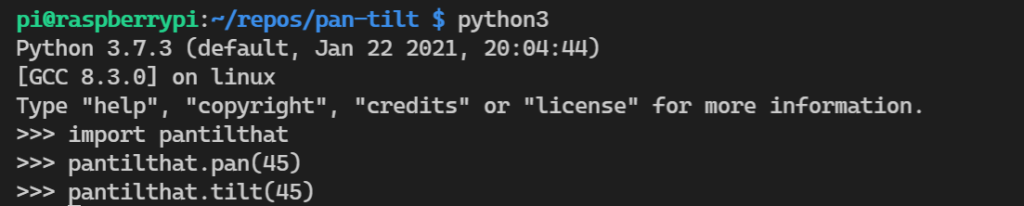
Start up python in the VSCode bash terminal. Import the pantilthat library. The documentation has a few methods we can try out. We’ll start simple using the pan() and tilt() methods passing in the angles within the allowed range.
One hop this time 🕺
Great! It works. Playing around a little we can see the angle changing.
Hi WALL-E! 🤖
Queue music for interpretive machine dancing through numerous function calls… 🤣
All done! Before we close out, the documentation suggests it’s a good idea to turn of the servo drive signal to save power if we don’t it to actively point somewhere using the pantilthat.servo_enable(index, state) function. Reset the servos to their original position, and used the function to disabled the two servos. Now to shutdown the Pi and think about the next challenge. Getting the camera feed working, then on to object detection and tracking. I’d like to see if we can get the solution working with a Python venv though.
sudo halt
For fun 🎈
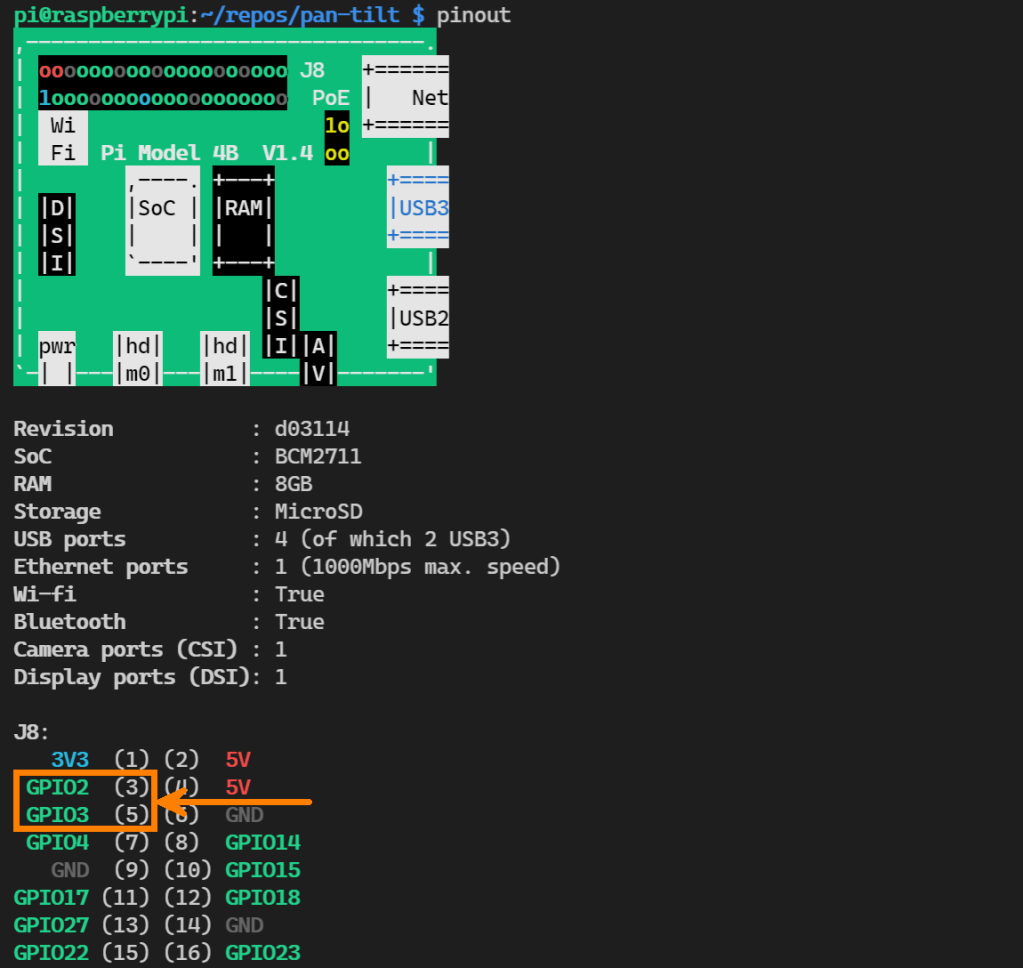
While perusing the documentation I noticed a note on displaying the Pi in the bash terminal which I thought was nifty. Give it a try…
pinout
Whaaaat! 🤯 Pi in bash!!
Summary
It’s been a quick post. Wrapping it up, we got our new pan-tilt hat installed, working, and dancing which brought a smile to my face. There’s heaps still to learn, I2C (I2C protocol), pinouts, and so much more. Most of which is new to me too.
Quick note 📝
A massive thank you to the many people who put their time and effort into projects, like the Pimoroni pan-tilt hat repo, which make things significantly easier for all of us.
We’ll work on the vision part in the next post. Camera’s, image capture, and even object detection. Once we have that done, we’re going to start working on connecting the device to the cloud.
TLDR; After a suggestion from a friend (Waylon Payne LinkedIn) we start learning about time series database InfluxDB. We set up InfluxDB on the Raspberry Pi by creating a database. Work on getting Grafana installed and running. We write, troubleshoot, and learn a bunch logging data to InfluxDB. Finally we create a dashboard in Grafana to display on Sense HAT telemetry.
Begin the Influx 🌌
Last time we tackled writing out SenseHAT readings to a csv on the Pi. Now though, we level up by working on writing that data to a database more suited for streaming log data, in this case InfluxDB.
A few things here to learn from the previous code snippets:
apt – Is a command line package/software management tool on Debian (Debian Wiki) like search, installation, and removal.
etc directory – Holds core configuration files. Found a nice Linux directory structure for beginners post.
wget – Is a command line package/software for retrieving files using HTTP, HTTPS and FTP, the most widely-used Internet protocols (Debian Wiki).
tee – Reads the standard input and writes it to both the standard output and one or more files (GeeksForGeeks).
source – Reads and execute the content of a file (GeeksForGeeks).
Best I can understand at the moment is that we get and store a public key that allows us to authenticate/validate the InfluxDB package when we download it by echoing the latest InfluxData stable release package and adding the package deb record to the source.list directory in a new file which seem to allow apt-get to pick up future updates. That kicked off the install of InfluxDB. How do we know? The console says so..
The influx begins!
It installs InfluxDB version 1.8.9 (not 2.0 which is the latest at the moment). Keep that in mind when working with documentation. Upgrading to 2.0 we can leave for the future. Onward!
systemctl – Is a command line utility to interact with systemd. It covers way more, but what I mostly used it for was working with the services.
Found the command to check a service status with the –help switch for the systemctl command. These all feel reasonably familiar coming from working a little with PowerShell and the Windows terminal.
sudo systemctl --help
sudo systemctl status influxdb.service
Running, running, running.
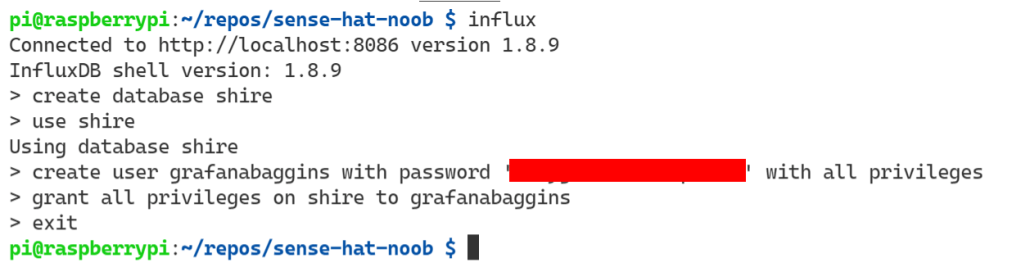
The service is up, active, and running. That means we should be able to connect to it. We can do that by logging into the Influx CLI from the terminal. Then creating a database. Creating a user. Finally, granting the user permissions.
influx
create '<yourdatabase>'
use '<yourdatabase>'
create user '<yourusername>' with password '<yourpassword>' with all privileges
grant all privileges on '<yourdatabase>' to '<yourusername>'
Ah familiar territory! A database! Now we have:
A database service running.
A database created.
A user that has more than enough permissions to interact with the database.
Grafana
We want a way to visualise the telemetry that’s going to be written into the database. Grafana gives us the ability to create, explore and share all of your data through beautiful, flexible dashboards and we can run the service on the Pi. We’re taking the same approach as we did for InfluxDB to get Grafana up and going. Getting all the packages, installing them, running updates, and validating the services.
Once the service is up we should be able to connect to it on port 3000.
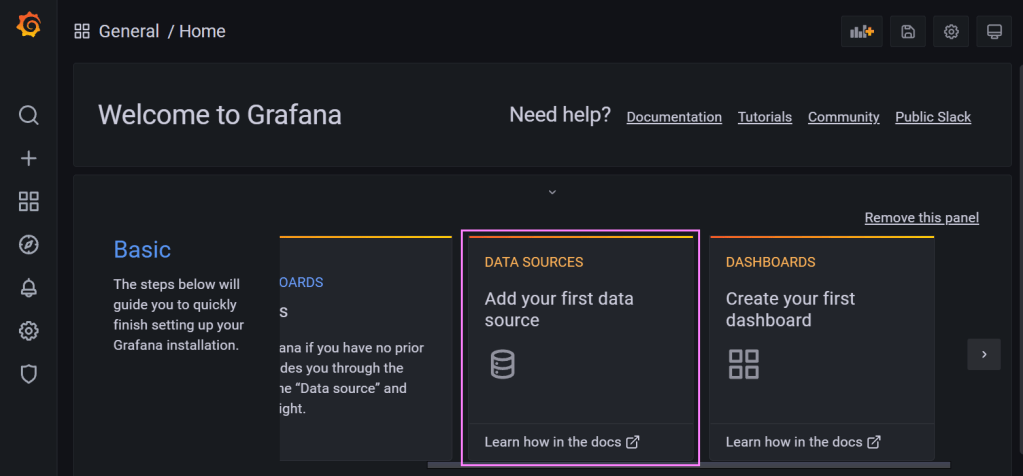
Yay! We’re connected. Let’s log in with the user name and password ‘admin‘ then reset the password. After the login process is done, we’ll land on the homepage for our Grafana instance running on the Pi. I’m actually excited about this 😄.
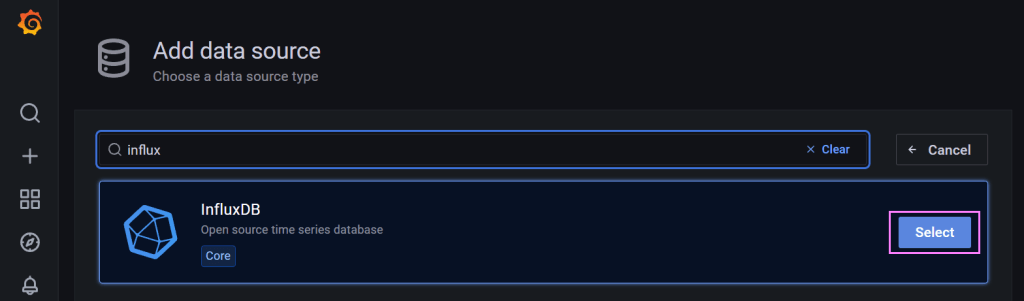
We need a way to connect Grafana to our InfluxDB database. On the Home page is a ‘Data Sources‘ tile which we can follow to add a data source.
Source of the action 💥
We can use the search box to lookup a connector for InfluxDB. Once we have that we just select it.
Search the unknown 🔮
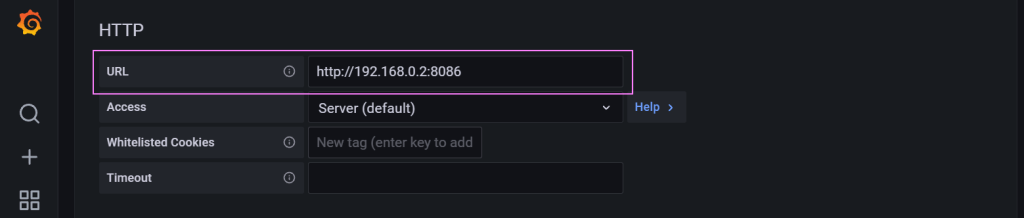
From there we configure the settings for the connector.
The way through the mountains 🏔️
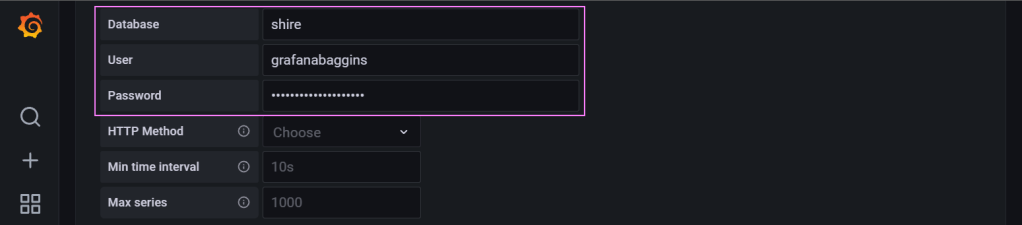
Credentials to make our way into the database.
You shall pass 🧙♂️
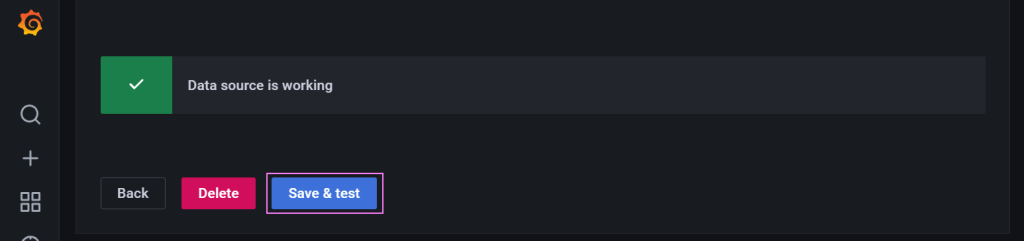
Finally, we save and test the connector to make sure its all working.
Green.. Green is good 🟢
Good news. The scaffolding is in place. Now we need to get data into the database then configure some dashboards.
Bilbo Loggings 🪵
“If ever you are passing my way,” said Bilbo, “don’t wait to knock! Tea is at four; but any of you are welcome at any time!”
– Bilbo Baggins
Did someone say tea? Time for a spot of IoT! Now to get our IoT device capturing data. A quick swish of our telemetry logging code and we have a starting point. All we need to do is figure out how to log data to InfluxDB not the csv.
Our virtual environment. It’s so smart. I think it reads my blog drafts 🤣. After we chose the interpreter, VS Code switches context to our virtual environment context. It even reminds us in the status bar at the bottom of the window. So thoughtful!
Our friendship will continue.
🚧 Slight detour 🚧
Slight digression from our regular blog flow...
Now, if you are briskly following along and haven’t switched to the venv in the terminal, then you will probably run into an error like this. Which might lead you on a wild goose chase across fields of learnings and wonder.
Goose chase begins 🦢
Naturally, we go looking to see if we find any packages for influxdb-client:
pip search influxdb-client
Which the PyPI XMLRPC API politely, in a crimson message, lets us know things are not as peachy as we hoped:
⚠️!Unmanageable load!⚠️
Fault: <Fault -32500: “RuntimeError: PyPI’s XMLRPC API is currently disabled due to unmanageable load and will be deprecated in the near future. See https://status.python.org/ for more information.”>
After updating the pip version in the venv, we check on the status which the error message suggested. After a very interesting read, a smidge of despair, hope emerges… I said to myself, “Self, why does that terminal not have the venv prefix?“. That’s when I realised the true source of the problem. Me. I forgot to activate the venv 😅.
For the terminal we still need to activate the virtual environment. To do this on the Pi we can run:
source <yourvenv>/bin/activate
Activates PEBKAC fix to end goose chase 🦢
Behold!!! It lives!!
When we do that, the terminal actually changes a little, giving us a visual cue that we are in a Python virtual environment. Now to get supporting packages installed so that we can write Python code for InfluxDB. Taking a look at the InfluxDB Client Python GitHub Repo or the influxdb-client PyPI project.
pip install influxdb-client
Goose = chased! 🦢
Sometimes Python can’t catch the programmer being the error.
~ me
🚧 Slight detourends 🚧
The packages are installed. The logging can begin. To get started we need to import the influxdb_client into our project.
from sense_hat import SenseHat
from datetime import datetime
from influxdb_client import InfluxDBClient, Point
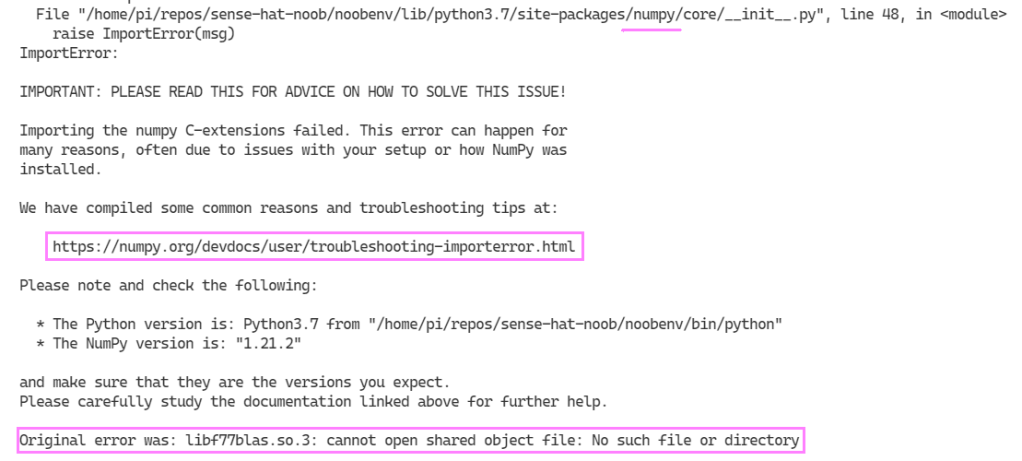
Yet again, we find a pebble in our shoe… While trying to import the sense_hat library modules in the REPL an error presented itself which seemed related to the way the numpy library was installed.
numpy dumpty had a great fall 🤣
The error message helps a ton! Jumping over to the common reasons and troubleshooting tips helps with options to solve the issue on a Raspberry Pi, if we use our original error “libf77blas.so.3: cannot open shared object file: No such file or directory“. I opted for the first option to install the package with apt-get:
sudo apt-get install libatlas-base-dev
Then tried to enter the python REPL again (just typing “python” while in the terminal) and importing the SenseHat module.
No one by that name here..
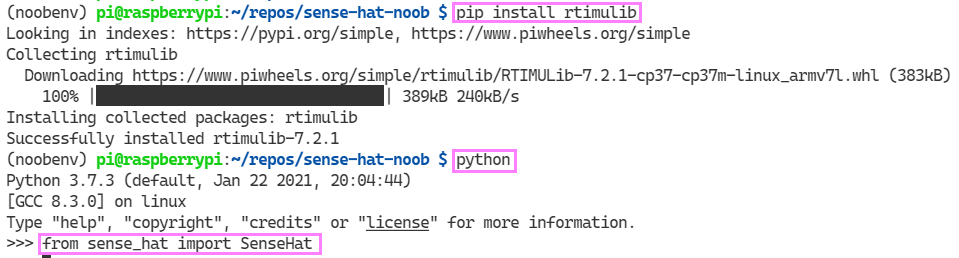
I am beginning to feel like a module hunter 🏹. I tracked down a RaspberryPi thread which led me to a comment on a GitHub issue for the RTIMU module error. To be clear, this doesn’t seem to be an issue when I am running in the global Python scope. Only an issue in the virtual environment. The folks were kind enough to provide a way to install this with a pip command. Here we go:
pip install rtimulib
Sparks joy ✨
Yes! It works!
I tried initially to write a Python function that would write to and query the database. It wasn’t long before I ran into an error trying to connect to the database using the Python function.
The settings are changed. To bring them into effect we need to restart the service.
sudo systemctl restart influxdb.service
Starting the engine
No much to go on. I found what seems to be a potential workaround. There is a comment further down in this thread on InfluxDB not starting that talks about adjusting a sleep setting for a start up file. Worth a try. Using nano again, we open the file and make the change.
Running, running, running 🏃
Time to write the code that will log records to our database. The idea is simple. Run a loop. Every few seconds get a Sense HAT reading. Log the reading to our InfluxDB. Stop the loop when we interrupt the program.
from sense_hat import SenseHat
from datetime import datetime
from influxdb_client import InfluxDBClient, Point
timestamp = datetime.now()
delay = 15
sense = SenseHat()
host = "localhost"
port = 8086
username = "grafanabaggins"
password = "<NotMyPrecious>"
database = 'shire'
retention_policy = 'autogen'
bucket = f'{database}/{retention_policy}'
def get_sense_reading():
sense_reading = []
sense_reading.append(datetime.now())
sense_reading.append(sense.get_temperature())
sense_reading.append(sense.get_pressure())
sense_reading.append(sense.get_humidity())
return sense_reading
# This method will log a sense hat reading into influxdb
def log_reading_to_influxdb(data, timestamp):
point = ([Point("reading").tag("temperature", data[1]).field("device", "raspberrypi").time(timestamp), Point("reading").tag("pressure", data[2]).field("device", "raspberrypi").time(timestamp), Point("reading").tag("humidity", data[3]).field("device", "raspberrypi").time(timestamp)])
client = InfluxDBClient(url="http://localhost:8086", token=f"{username}:{password}", org="-")
write_client = client.write_api()
write_client.write(bucket=bucket, record=point)
# Run and get a reading Forrest
def run_forrest(timestamp):
try:
data = get_sense_reading()
log_reading_to_influxdb(data, timestamp)
while True:
data = get_sense_reading()
difference = data[0] - timestamp
if difference.seconds > delay:
log_reading_to_influxdb(data, timestamp)
sense.show_message("OK")
timestamp = datetime.now()
except KeyboardInterrupt:
print("Stopped by keyboard interrupt [CTRL+C].")
I struggled for a while trying to figure out the bucket/token variable to what I was able to do in the 1.8.9 CLI easily. I revisited the Python client library and noticed a specific callout for v1.8 API compatibility which has an example that helped me define the token. It wasn’t long before we got the script running and data was being logged to the database.
We’re getting there!
To the Shire
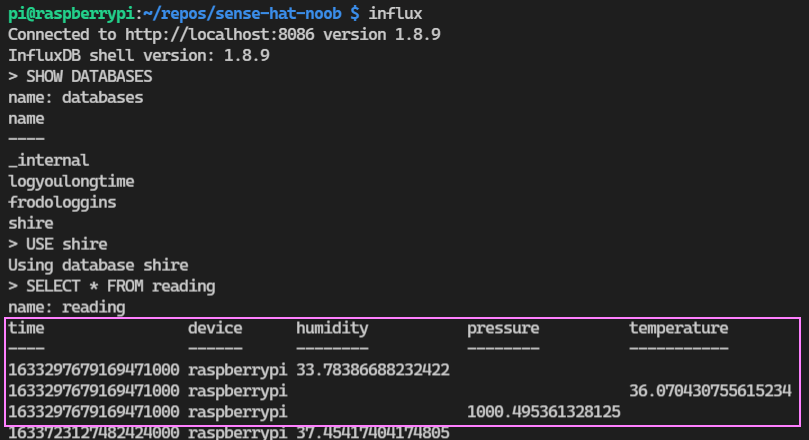
Before we get started on logging data to the database we need to understand some key concepts in InfluxDB. It won’t be the last time I visit that page, these concepts are foreign to me. I learnt to use InfluxQL which is a SQL language to work with the data. There are some differences between Flux and InfluxQL that you might want to keep in mind. I had a tricky time figuring out how to execute Flux queries initially after I wasn’t getting any data back from my Flux commands in a Python function, but saw that you could invoke a REPL to test queries with). To keep things simple though, I opted for InfluxQL. We can launch the Influx CLI from the terminal and query our data.
influx
SHOW DATABASES
USE <database>
SELECT * FROM <table>
Successfully captured! 🪤
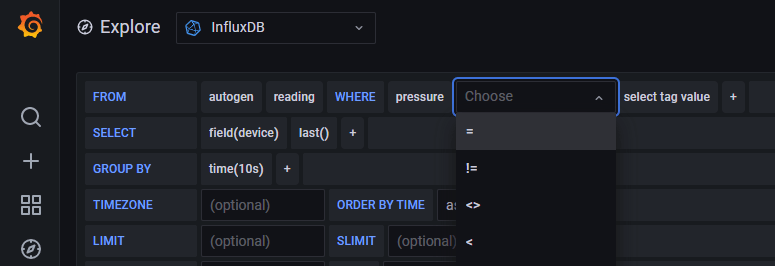
Let’s see if we can build a dashboard to visualise the data we are logging. We can connect to our Grafana server again. Head to the home page. There is a “Explore” menu item that is a quick way for us to query our data and experiment. Once the window opens up we select our data source connection from the drop down box and begin building a query with a wonderfully simple interface.
Visual query building 🤩
It’s at this point we realise that our logging design might not be correct. What I was expecting was that I could use the columns in the SELECT and WHERE clauses. Apparently not. I initially thought that design would work better because I understood that tags were indexed, not fields, so querying the tags would be faster. Good in theory, but I couldn’t reference the tag in the SELECT and WHERE clauses. My initial mental model needed tweaking. A change to the logging function to log to a single point, not three, with multiple fields.
point = ([Point("reading").tag("device","raspberrypi").field("temperature", data[1]).field("pressure", data[2]).field("humidity", data[3]).time(timestamp)])
Minor InfluxDB management needed in future to clean up the database. For now though, we have our ‘frodologgins‘ database which is empty. I ran the logging function against the new database and…
* Chef’s kiss *
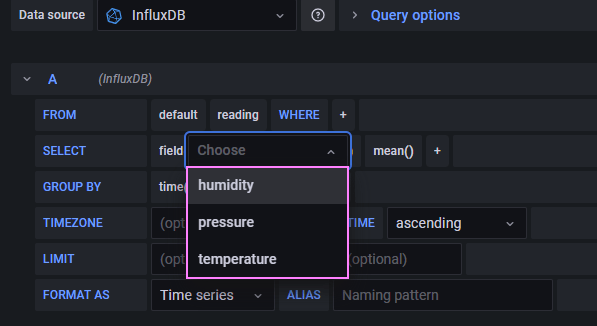
It works as expected! A quick updated to the Grafana connection settings to switch to the new database. With the updates in place we now get the expected results in the drop down. We can see the fields we want to display and chart.
We can try reconcile the point, tags, and field in the Python code to how we are querying it with InfluxQL. Slowly sharpening our mental model and skills. The query reads as follows:
From our database
Query our readings for the default/autogen retention policy
Where the device tag value is raspberrypi
Return the last temperature field reading
Group by ten second intervals
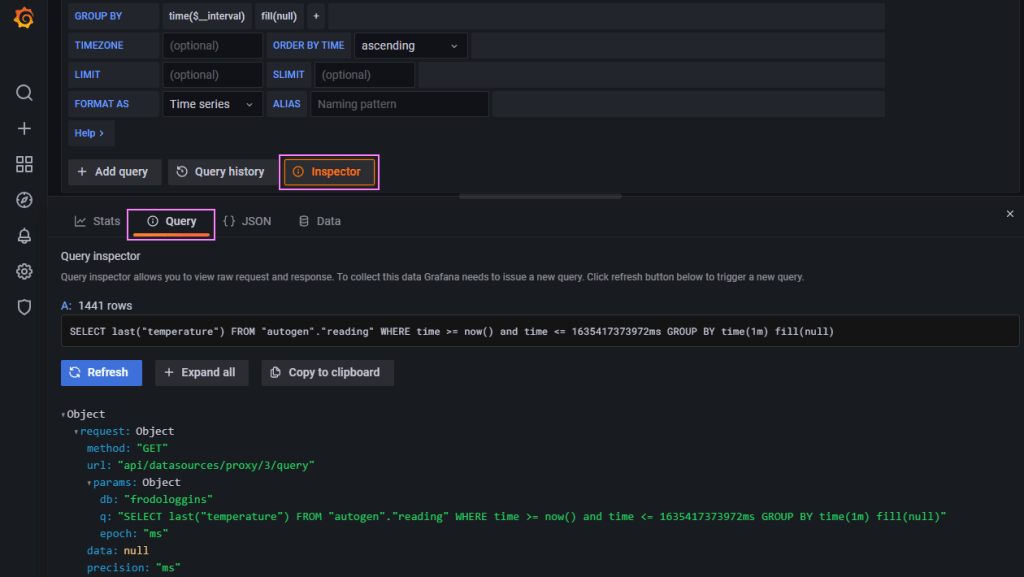
One thing I wasn’t quite sure of is the way that the time range worked in Grafana with the data logged in the database. The query looked correct but no data was returned. I was looking at a window from now-1d to now initially. It seemed logical to me, “find me all the data points from yesterday to now“. The Inspector in Grafana helps get the query and then we can use that to run the query in the Influx CLI to test the queries.
Inspector Clouseau 🕵️
I eventually adjusted that to now to now+1d which in my mind is “back to the future” 🔮🚗, but it worked. I think this comes down to how the dates are stored (i.e. timezone offsets) and the functions evaluation. I’ll dig into that later, for now this works, we have data showing on a graph.
Graph
Let’s take the learnings and apply it to building the dashboard. Head to the home page. There is a “Dashboards” tile we can use to build our first dashboard.
Dash lightning! 🌩️
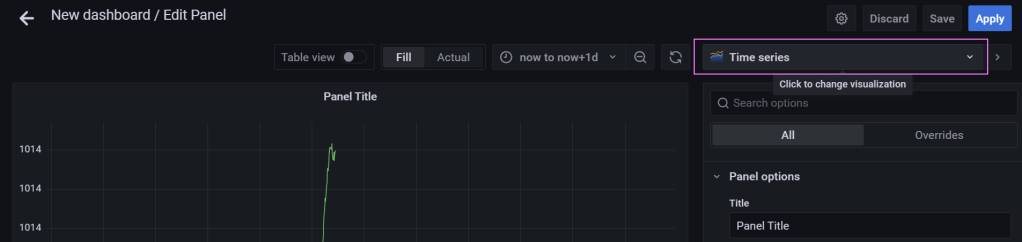
It opens up a new editing window. I chose an empty panel. From there we can edit the panel in a similar way to what we did with the Explore window. In the upper right corner we can choose the type of chart.
Serious time ⏳
There are a bunch of options from changing the charts, adjusting threshold values for the gauges, applying units of measure, and so much more. For our case that’s “Time series“.
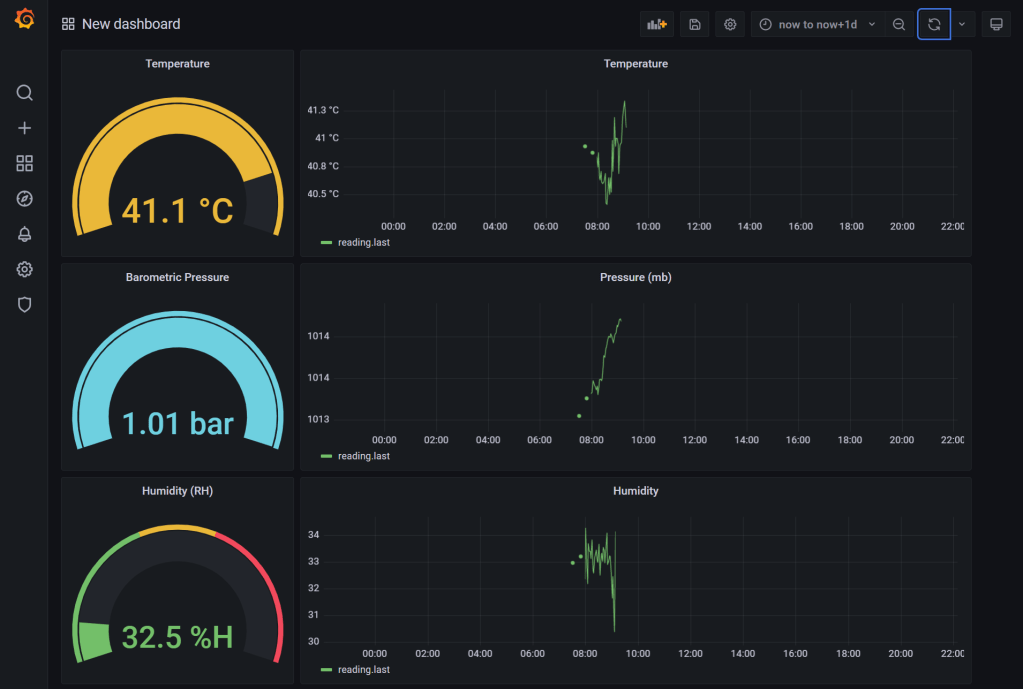
That’s it! Use the same approach to build out the other charts. I added “Gauge” visuals as well with the corresponding query.
Ice, Ice, Baby 🧊
Learnings 🏫
We made it! It took a while but we did it. Failure is a pretty good teacher. I failed a bunch and learnt a more. That’s not wasted time. It’s worth just getting hands on and trying different things out to build the mental model and skills. I have a long way to go to really understand Python, InfluxDB, Grafana, and Linux but I’ve made progress and learnt new things which is a blessing.
If you are wondering how I am writing code remotely on the Pi, go check out setting up remote development on the Raspberry Pi using VS Code. We are using the same approach here to get connected and working on our Pi.
Part of this journey is growing my skills. I chose Python as a programming language. Not diving into too many details. It just gives a range of capabilities (web through to machine learning) with a single language. No need to switch too much while learning all the techs in this series. Works for me.
While upping my Python game I came across something called virtual environments. A little primer on virtual environments. I think I have a reasonable grasp on how to start using them for better package management.
Not going full virtualenvwrapper yet though. “Hey, I just met you and this is crazy, but here’s my bookmark, browse it later maybe. #justsayin’
To that note, let’s set up a virtual environment. First, check our Python versions on the Pi:
python3 --version
Snake in eagle shadow 🐍🦅
We have Python3 installed on the Pi. That means we should have the venv capability built-in. Let’s give it a whirl!
python3 -m venv noobenv
Environment cultivated
When we do that a new folder gets created in our repo. It has a bunch of folders and files related to the “inner workings” of how virtual environments work <- science 👩🔬.
Logging the things 🪵
The goal here is that we have an IoT device that is capturing data from the sensors. It has a bunch of sensors we are going to use, which is exciting. Honestly, the more I work with it, the more amazing it is to me.
from sense_hat import SenseHat
from datetime import datetime
sense = SenseHat()
def get_sense_reading():
sense_reading = []
sense_reading.append(datetime.now())
sense_reading.append(sense.get_temperature())
sense_reading.append(sense.get_humidity())
sense_reading.append(sense.get_pressure())
sense_reading.append(sense.get_orientation())
sense_reading.append(sense.get_compass_raw())
sense_reading.append(sense.get_accelerometer_raw())
sense_reading.append(sense.get_gyroscope_raw())
return sense_reading
We create a function (get_sense_reading) that we can call repeatedly. Then use the SenseHat functions (e.g. get_temperature) to get readings from the different sensors. To get them all in a single object/row, we can use a list (sense_reading). Then append each reading to the list. Once we have them, we return the list object.
Witness the quickness ⚡
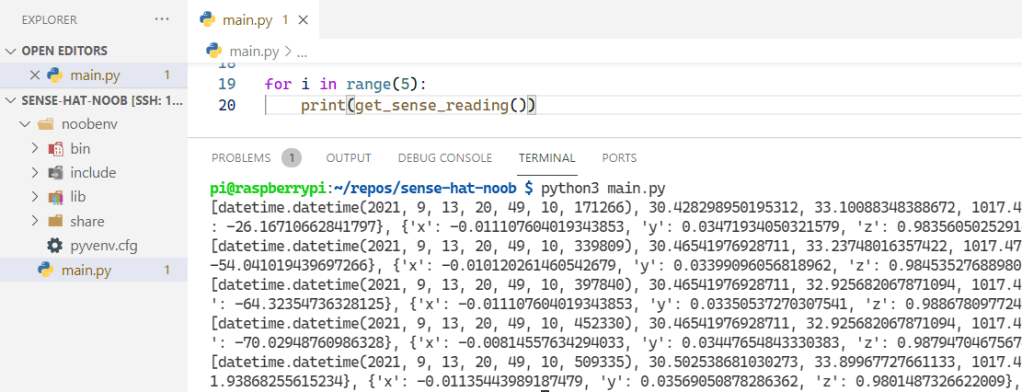
We add a for loop to our code to call the get_sense_readingfunction a few times are print the results to the terminal window. We can run the program (main.py) by calling the Python 3 interpreter and passing the file name to it. That loads the code, executes the loop, prints the results.
python3 main.py
Now to add data to a file on the device. We’ll use a CSV for now, then adapt it later based on our needs. We can use the the sense_readingobject returned by the get_sense_readingfunction and write that to the file using the csv library.
from csv import writer
timestamp = datetime.now()
delay = 1
with open("logz.csv", "w", newline="") as f:
data_writer = writer(f)
data_writer.writerow(['datetime','temp','pres','hum',
'yaw','pitch','roll',
'mag_x','mag_y','mag_z',
'acc_x','acc_y','acc_z',
'gyro_x', 'gyro_y', 'gyro_z'])
while True:
data = get_sense_reading()
difference = data[0] - timestamp
if difference.seconds > delay:
data_writer.writerow(data)
timestamp = datetime.now()
We start with a timestamp because we want to calculate a delay interval, say 1 second, between writes to the file. The open the file and write a header row (writerow) to the file. We use a while loop to collect readings, then once we exceed the delay interval, write the row to the file. We need to update the timestamp otherwise we will write a row on every pass after we exceed the timestamp the first time.
Testing seems to be working and we can log data to a file on the device. VS Code integrated terminal really is fantastic at running multiple and side by side shell/terminal windows.
A tail of two terminals 💻
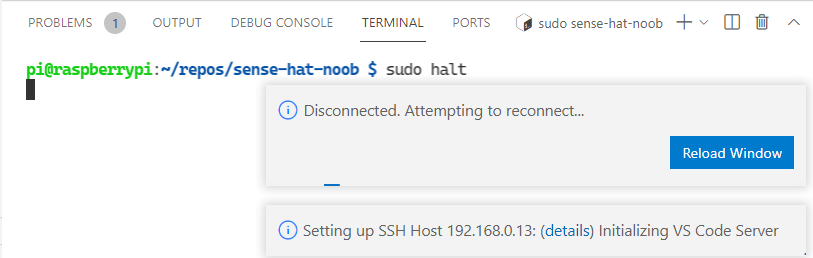
Awesome! It works. We have a program logging data to a csv file at a defined interval. Tail simply prints end of file content. A few lines is all we need to double check things are working. Last thing left.. shut down the Pi remotely. Usually I would use a shutdown command. I gave a new command a try “Halt”.
sudo halt
Halt! Who goes there? 🛑
Looks like that worked 🙂 The connection got terminated and VS Code detects that, and tries to reconnect. Pretty slick. We managed to start putting new Python skills to use. Learnt how to create a virtual environment for better package management. Then collecting and writing telemetry from the SenseHat to local storage on the Pi.
We want to work remotely on the Pi (the artist formerly known as Raspberry Pi 🕺). Sticking with VS Code, there is an extension to help us do remote development:
Remote extensions
This Remote Development extension pack includes three extensions:
Remote – SSH – Work with source code in any location by opening folders on a remote machine/VM using SSH. Supports x86_64, ARMv7l (AArch32), and ARMv8l (AArch64) glibc-based Linux, Windows 10/Server (1803+), and macOS 10.14+ (Mojave) SSH hosts.
Remote – Containers – Work with a separate toolchain or container based application by opening any folder mounted into or inside a container.
Remote – WSL – Get a Linux-powered development experience from the comfort of Windows by opening any folder in the Windows Subsystem for Linux.
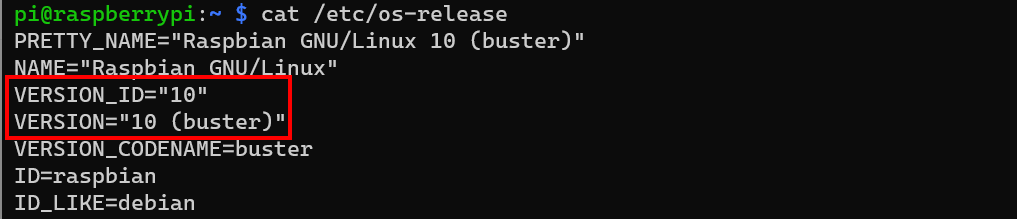
Now the one we are after for the time being is the Remote – SSH extension which allows me to connect to the Pi over SSH. It’s not as simple as that though. Look at the architectures supported. We need to make sure our Pi has one of those architectures. Looking at the extension documentation we can see it supports: ARMv7l (AArch32) Raspbian Stretch/9+ (32-bit).
When we previously SSH into the Pi we get a glimpse of the architecture version:
Version dePi
To get the OS version we can use the cat command to find the release information:
cat /etc/os-release
Buster Pi
We have a supported configuration. Let’s try to connect remotely via SSH to our Pi with VS Code using our new extension pack. Open the Command Palette and type “remote-ssh”. Look for the “Connect to Host…” option:
Contact 📡
Then select the platform for the host. In our case Linux. Raspbian, the Pi-specific OS, is a Linux distribution based on Debian. Fill in the login credentials to finish establishing a connection.
One thing I spotted was the prompt in the bottom right corner of VS Code which was connecting via SSH, nice, and “Installing VS Code Server”. Wait, what? Which looking at the architecture, seems related to the way VS Code Remote Development works. A bit more than I am going to dig into here:
Deploying
Eureka! We are connected remotely to the Pi! Take a look at the VS Code status bar in the bottom left. Notice that it says “SSH:<ip of Pi>” and the Terminal window is a bash shell running connected to the Pi.
Ssh.. Terminal likes Pi too
Now that we are connected remotely to the Pi. Let get’s started with the Sense HAT. First things first, software updates. I am learning about Linux as I go here. Standard users by default aren’t allowed install applications on a Linux machine. To update the software we need to escalate privileges. The “Run as Administrator” in Linux terms seems to be “sudo“. I’m team “super user do” just sounds epic. Then apt-get update/upgrade to invoke the package handling utility to update or install the newest version of packages on the system.
sudo apt-get update
sudo apt-get upgrade
Yep.. updates
I ran both commands (only one shown for brevity). They ran like a charm 🍀. The upgrade pulled all it needed, created a few diversions, seemed to unpack it’s bags, set itself up, and process what just happened. I don’t know about you, but our Pi seems to have gone through a big phase in it’s life 🤣. Our Software is updated. Now to install the sense HAT software:
sudo apt-get install sense-hat
Already the new and shiny
Nice! Our sense HAT software is up to date. Let’s start writing some code. What is awesome though is that there is an online emulator (trinket.io) that you can use to code the sense HAT in your browser if you don’t have one! Next up, we figure out how to set up new directories for the code with mkdir:
mkdir repos
cd repos
mkdir sense-hat-noob
cd sense-hat-noob
Now once that’s done, VS Code can pick up the new folder and we can open it using the regular “Open Folder” option in the “File” menu:
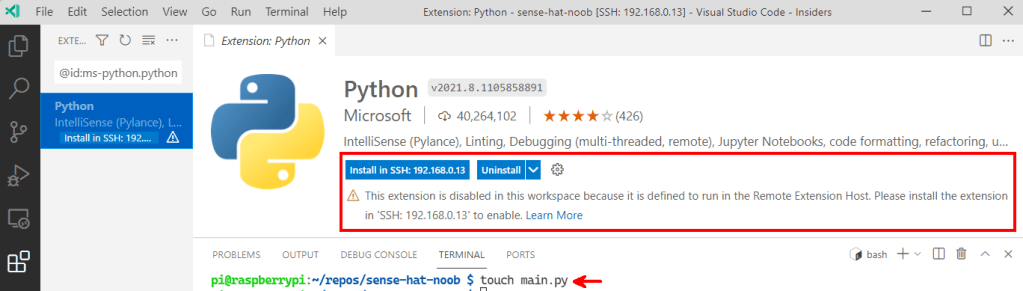
Now to add a file and write some code. To do that we are using the touch command. The moment we do that, VS Code noticed it’s a Python file extension and popped-up to ask if we want to install the recommended Python extensions.
Why did it have to be snakes? 🐍🤠
What is interesting is that it suggests the extension should be installed on the Pi 🤔 Again, this is related to the architecture for remote development. I tried not smiling about this, but apparently this extension has preferences…
There not here
Okay. We have reasonably secure remote connectivity, remote extensions, code file, no we need some code. Thanks to the new remote extension we have IntelliSense(Pylance) running:
I sense intellisense
I wrote some code to display a message on the LED face. There are a bunch of parameters for the function, let’s keep it simple here:
from sense_hat import SenseHat
sense = SenseHat()
sense.show_message("Hello world")
Viola! This sparks joy! The Pi displays it elation! I got a snap of the exclamation marks scrolling across the screen (pretty cool catching the one LED off as the characters move across the face).
Spark Joy
That’s it for this one. Tons of new learning experiences. We are making progress! If you have any ideas or suggestions on things that can be done better. Let me know.
Now that we have the code set up and we can deploy it manually it’s time to autobot automate. We are going to use GitHub Actions for Azure to work on building our Continuous Integration/Continuous Deployment pipeline.
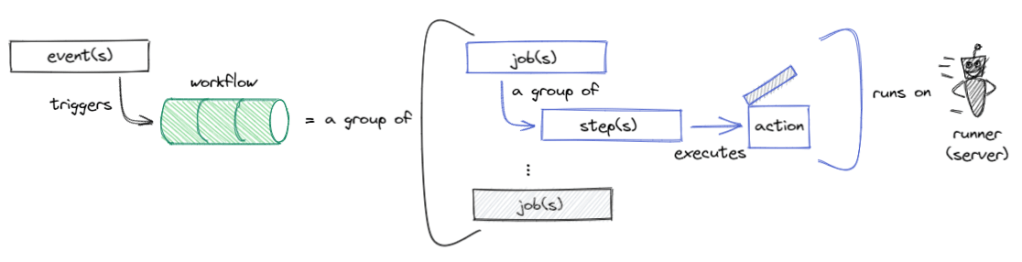
What we are looking to create is a workflow to automate tasks. Actions are event-driven. An example is “Run my testing workflow when some creates a pull request.”. What makes up a workflow? Queue Intro to GitHub Actions. To start off the thinking I get to test out a pretty fantastic open-source whiteboard tool, with tons of potential, called Excalidraw. *Inner voice screaming… “Excalidraw, I choose you!”* ⚔️
Working the flow.
A workflow is an automated procedure that you add to your repository.
A job is a set of steps trigger by event/webhook or scheduled that execute on the same runner.
A step is an individual task that can run commands in a job.
Actions are standalone commands that are combined into steps to create a job.
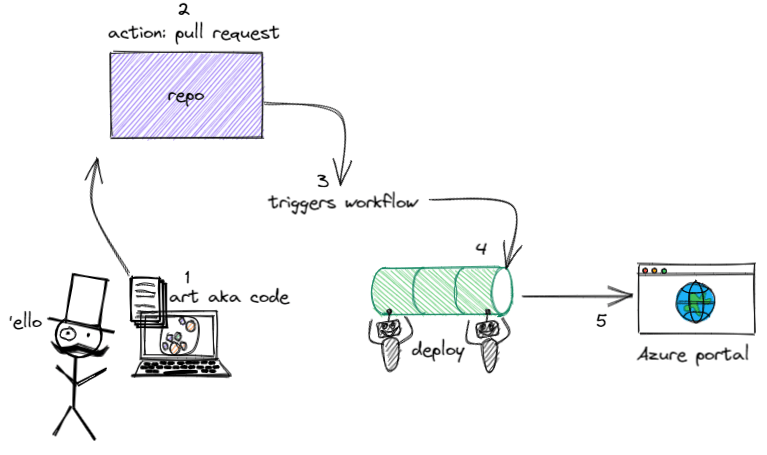
Now that we know some basics, let’s dive in and give it a go. Here is the plan for what we want to achieve with an accompanying artistic depiction:
Develop some code, commit to our branch, push the changes
Then complete a pull request and merge the changes
The GitHub action triggers the workflow
The workflow runs our jobs and steps to deploy the resources
Validate the resources got deployed to Azure
Hard at work.
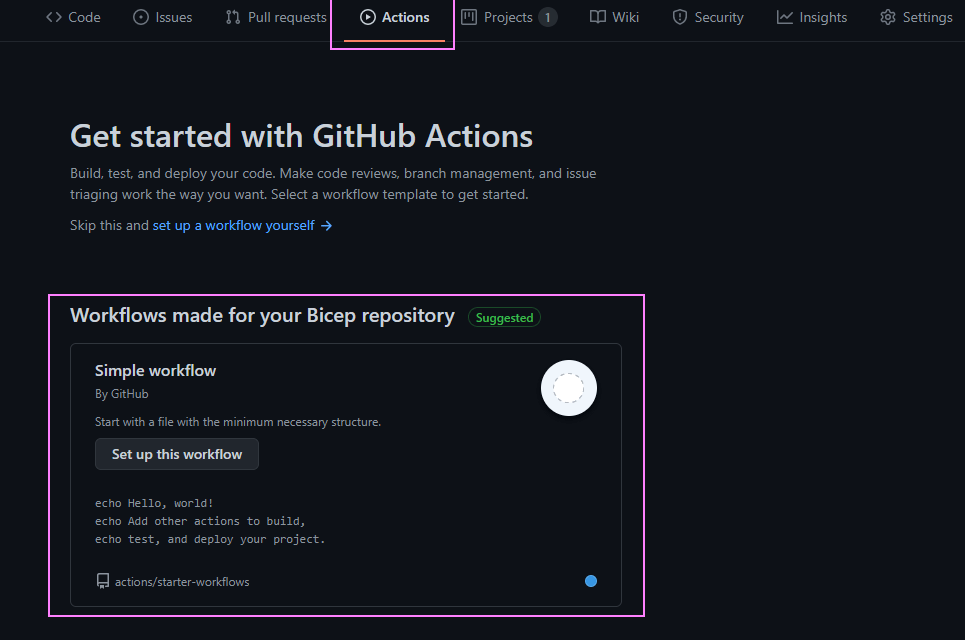
Let’s create our first GitHub Actions workflow. Navigate to the ‘Actions‘ tab in our repo. We get a few workflow templates we can use. Let’s use the ‘Simple workflow‘ by using the ‘Set up this workflow‘ button.
And Action 🎬
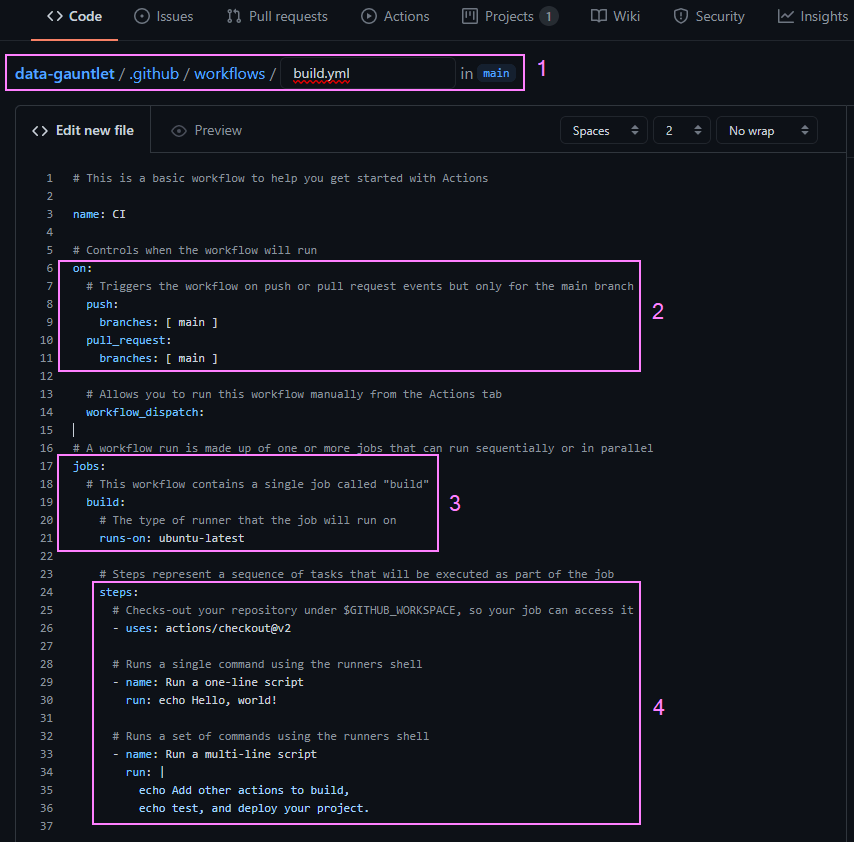
GitHub actions use YAML syntax for defining events, jobs, and steps. When we created the workflow, GitHub added a new .github/workflows directory to our repo. It created a new .yml file which I renamed to build.yml in that directory. For those of us that don’t speak YAML fluently, we can learn x(yaml) in y minutes 🧪.
Yay YAML!
A brief summary of what is going on here:
Our new YAML file and path was added to our repo
We can see our workflow is triggered on a push or pull request actions to our main branch
We have one job that runs on a Ubuntu runner server
That’s a good enough starter template. From this point on, for brevity, I followed the documentation to deploy Bicep files by using GitHub Actions. That covers setting a deployment service principal (My choice, Windows TerminalPrettified), configuring GitHub secrets, and the sample workflow to deploy Bicep files to Azure. Once that is all set up, we have a workflow that looks like this:
Note: Though not the recommended practice. I adjusted the scope of my service principal to a subscription level. For my testing I would like GitHub Actions to create resource groups using my Bicep file definitions not the CLI. So my command was a little different:
az ad sp create-for-rbac --name {myApp} --role contributor --scopes /subscriptions/{subscription-id} --sdk-auth
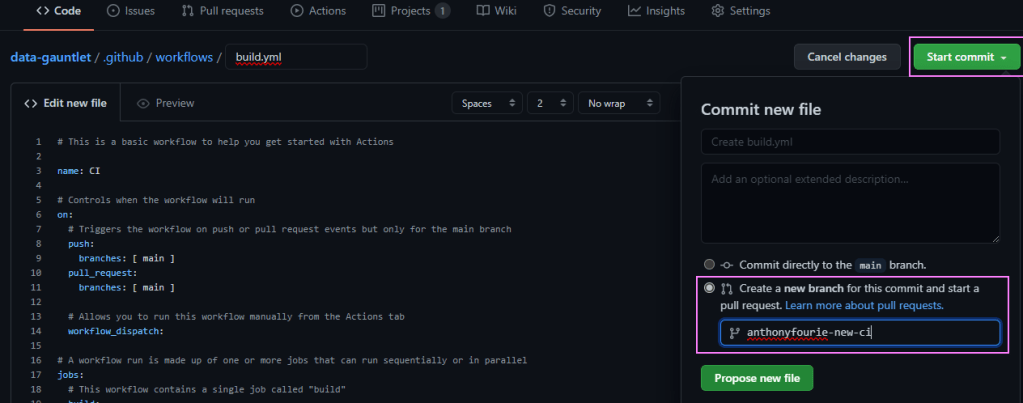
To commit our changes, just use the ‘Start commit’ button in the top right corner. I created a new branch from here for the change, then just finished the pull request from there, merging our changes to the main branch.
Committing to it
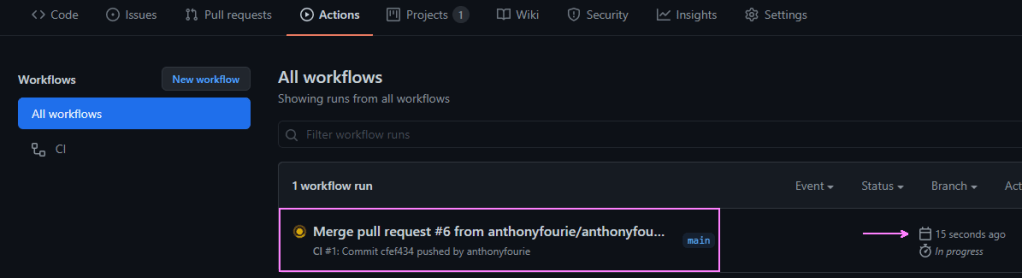
Remember our triggers? On pull_request to main? That kicks off our pipeline 😎
Behold! It lives!
Full disclosure: It failed. lol.
I got an error “missing ‘region’ parameter” for the Azure/arm-deploy action
I adjusted the file path for the ‘deployAnalyticsPlatform.bicep’ file from root to the src/bicep directory.
I also modified the trigger to only fire when a push is done to the main branch. That prevents us running the pipeline twice, once for the pull request, then again when the merge us run.
So we learn 😉
Re-calibrating
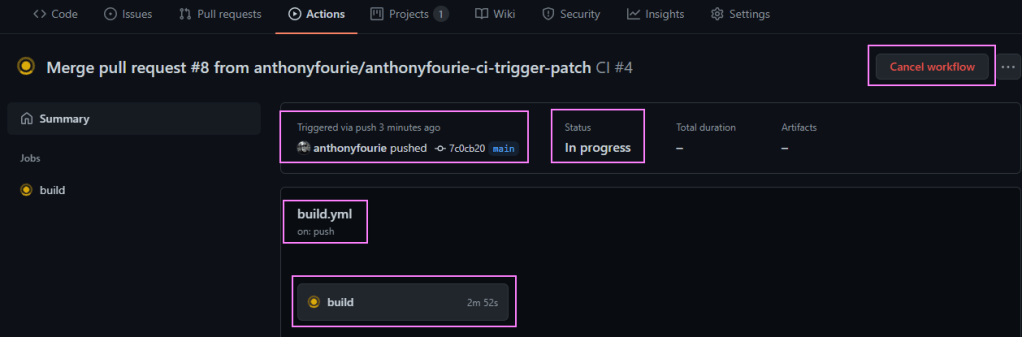
Quick update to the code. Run through the GitHub flow again and we are back in business. When we navigate into the Action we can see a bunch of information. Why the workflow was triggered. What’s the status. Which jobs are running.
In flight
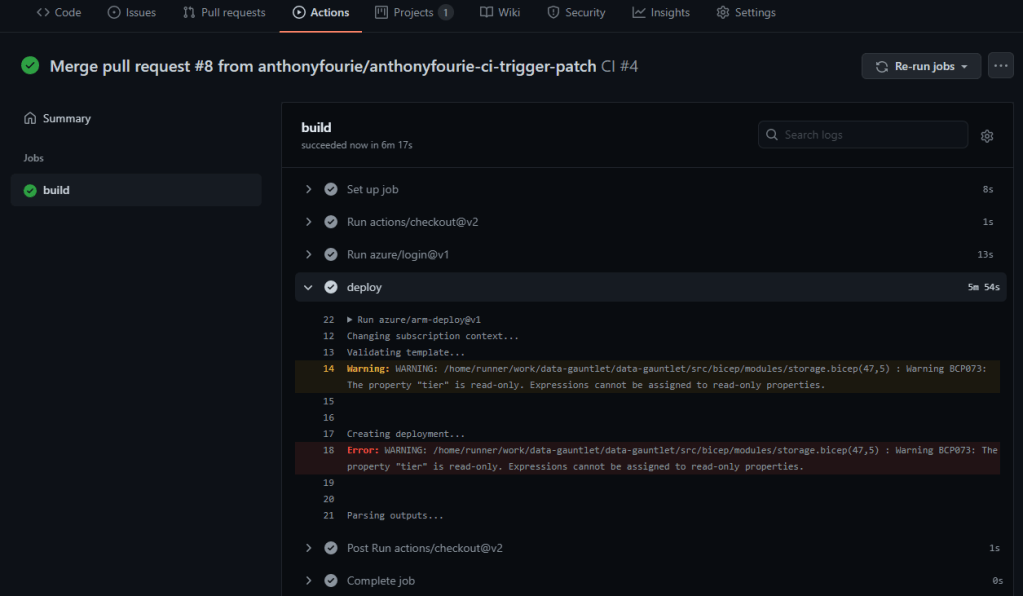
When we click on the job, we can drill into the runner logs as well. This helps a bunch in debugging workflows. An example, is that we have a property for the storage account which is read-only:
Only reading errors
The deployment succeeded though which I think is great progress!
Deployed with action!
That’s it! All done. Explored GitHub actions. Created service principals and GitHub secrets. Learnt some YAML. Broke and fixed our workflows. Then successfully deployed resources from Bicep code.
TLDR; My very first Pi and sense HAT was graciously gifted to me by Jonathan Wade (LinkedIn). I assembled it. Tried to go headless. Ended up adding a head because reasons. Ran through initial setup and updates. Configured OpenSSH on Windows and SSH on the Pi to get to the headless state.
I got gifted something amazing! Yup, my first Raspberry Pi. Not only that, a Sense HAT too! Now for many people that might mean much, but this is a pretty big moment for me. To save you from another unboxing experience I took the liberty by doing that privately and cut to the end. Behold! The unboxed product:
Bare metal
Looking through what we have here. The Raspberry Pi 4 Model B (top left), the Raspberry Pi Sense HAT (bottom middle), a SanDisk 32GB microSD card, some spacers, screws, power cable, and a HDMI to mini HDMI cable.
Fresh off the factory floor
Assembling the unit was really simple. Just a quick look at the Sense Hat board and we can see some amazing things:
Air Pressure sensor
Temperature and humidity sensor
Accelerometer, gyroscope, and magnetometer
8×8 LED matrix display
Even a small joystick!
This device is pretty EPIC and it’s not even powered it on yet. So many things I haven’t ever worked with but can’t wait to try and figure them out.
Like a diamond 💎
Next up power and networking. The moment I connected the power a rainbow 🌈 filled the room. A sign of a pot o’learnings 🪙 to be found at the end of this experience.
Nice! Now we have the whole unit assembled. What’s the plan? Well, the thinking is to use this to deploy and run Azure SQL Edge on it. Why? A few reasons:
I have never worked with a Raspberry Pi
I haven’t really work on Linux at all
I have never done any work with Azure IoT solutions, or IoT at all for that matter
I do know Azure SQL reasonably well, though not Azure SQL Edge
That didn’t work. Apparently SSH has been disabled by default. Considering I don’t have a microSD card reader, it’s time to put a “head” on nearly headless Pi and connect a screen 🖥️. The HDMI cable, a keyboard, and a mouse later and we are connected. I ran through the setup, updated the password, downloaded the latest updates, then set up SSH. There are other security best practices that I am going to follow as well after this post. Then tried to connect again and…success!
Connection suck seeds! 🌱
Next I shut the Pi down. Disconnected the screen, mouse, and keyboard. I’m going to try work on this device remotely so I don’t need those peripherals right now.
Now that we have an IoT device I am going to start exploring if there are any open data sets that I can start using and feed some of the device telemetry into the end-to-end analytics solution as a cohesive project. We are going to set up additional services in our solution to support IoT device which will be fun.
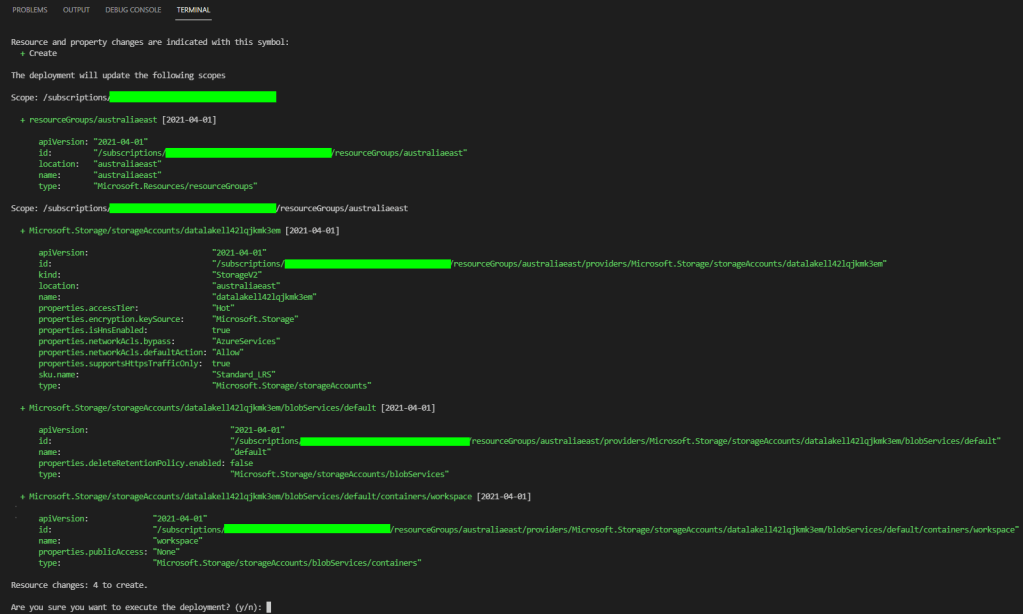
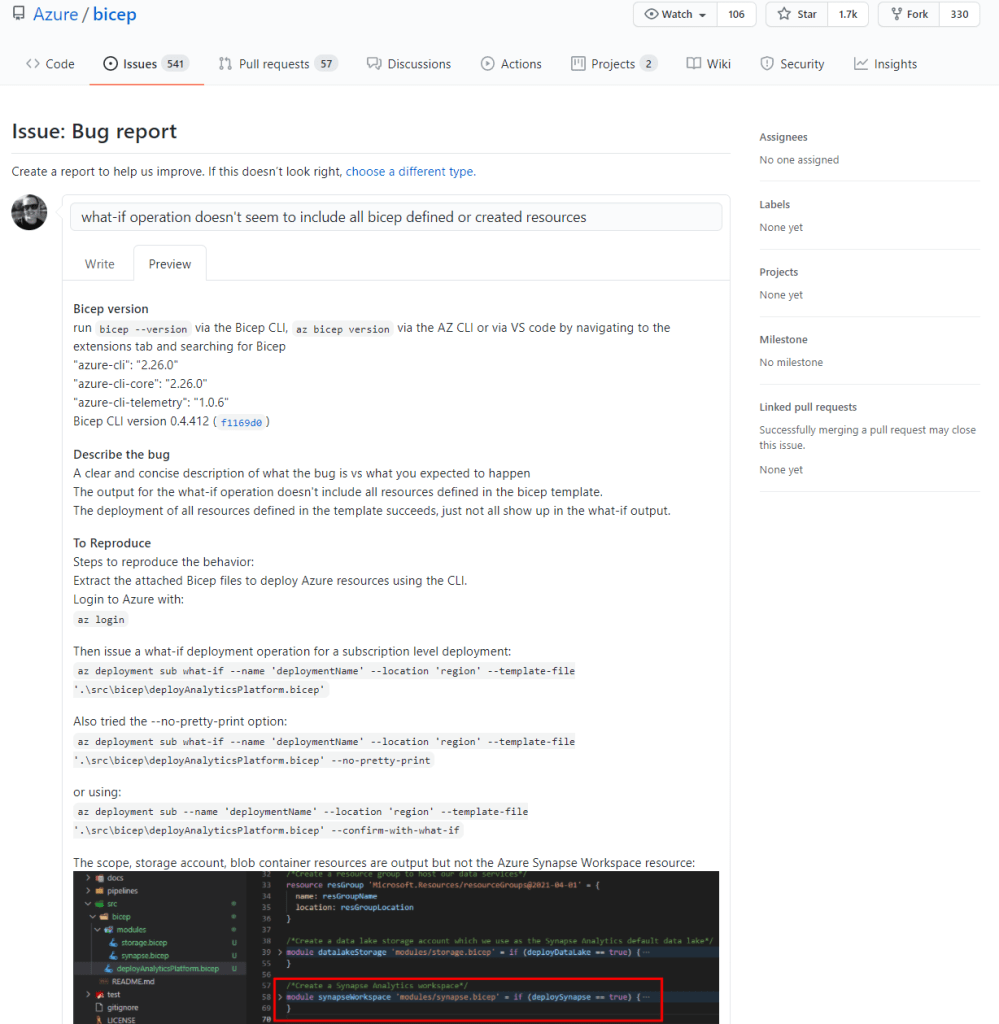
TLDR; After I refactored my code to use modules I found that Bicep supports ‘What-If’ operations which explain what the code is going to do before deploying it. This post I do a short test on that. Found an issue not showing Azure Synapse resource creation. Then browsed the Bicep GitHub repo to search issues related to What-If operations. Didn’t find what I was hoping for, so logged my first public GitHub issue 😁.
Update: The issue we encountered seems to be related to another preflight improvement which is being worked on but is a “…bit of a gnarly, low level issue so please be patient 🙂“. I was amazed to see how quickly Bicep the team responded on this.
az deployment sub create --name '<name of deployment>' --location '<location name>' --template-file '<path to bicep file>' --confirm-with-what-if
Side note: I had to change the VS Code theme to save us all from the agony of lime green on light grey background reading.
What’s nice is we get a breakdown of changes that we are about to apply to our environment. I think that is awesome.
I have one question. Explosions? 🧨
Yes, for the eagle-eyed reader, I realised my storage account name is an Azure Region name hahaha 😂
Looking at the terminal output, reading top to bottom, I can see:
We are about to deploy at the subscription scope.
We are deploying a Azure Data Lake Gen2 Storage Account with blob container and all their configuration goodness.
We are deploying an Azure Synapse… wait a minute…
What was weird was that I didn’t see the Synapse Workspace. I checked the deployment details/output and it was there.
Deployed
I wondered if the reason it didn’t output the Azure Synapse Resource during the What-If was because I didn’t define any output variables for it which I did for the storage account.
Putting more out.
I updated my variables, added output variables for my synapse.bicep module, then ran the What-If again. Aaaaand…. nothing changed. Considering Bicep is an Open Source project on GitHub we get to search for issues with ‘What-If’ operations. So, we get to create a issue 😁 Taking the things learnt over the past few posts on
The what-if behaviour doesn’t block us at this stage. The deployment works so at this point I think we are set for the next section to work on getting this into a GitHub Actions pipeline.
We can use modules to group a set of one or more resources to be deployed together. We can reuse modules for better readability and reuse. They basically get converted to nested ARM templates from what I understand.
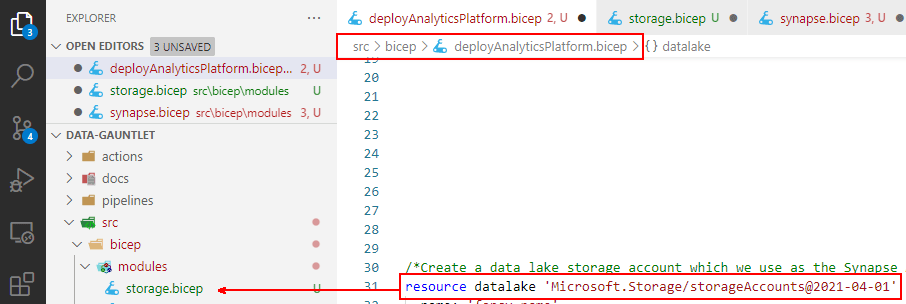
The first part that I want to move int a module is the data lake storage account and resolve dependencies. When that’s done, repeat the process for the other resources that we want to deploy.
Moving day.
Next up, update modules to use parameters and variables where possible to avoid hard coded values. We should be in a position where the module is bit of code that can be called with a set or parameters. Note that when the resources are in the same file, you can reference them directly. An example from my previous post was were I reference the datalake resource.
Same file resource references.
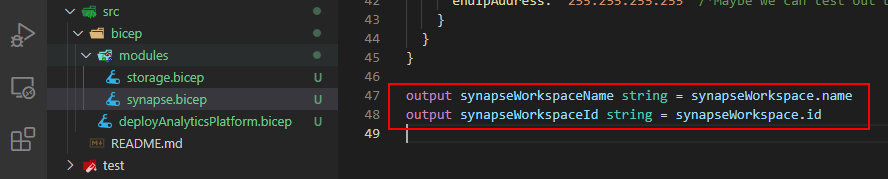
A module only exposes parameters and outputs to other Bicep files. When we move the data lake resource creation to a module, we need to leverage outputs which can then be passed between modules. The idea is to call a module -> deploy the resource -> output important things -> pass those things to another module as input parameters. So, the same property I referenced before now becomes an output in the module of the storage account:
Output for output.
Output variables can now be used in the main script as inputs to another module, etc. We just reference them using the module.output syntax.
Outputs as inputs.
We use operators in our deployments for things like conditional deployments.
On one condition.
Expanding on the use of parameters and variables, functions are a great way to drive flexibility and reuse into your deployments. Getting runtime details, resource references, resource information, arrays, dates, and more. Just remember most work at all scopes, some don’t. When they don’t you will probably figure that out with errors. One way to use them is to inherit the resource group location during resource deployment. In our case, setting variables with the resource group location, appending a deterministic hash string suffix for the storage account name from the resource group, or even enforcing lower case of names then using the variables for deployment.
Variables and functioning captain 👩✈️
FYI, the weird looking string notation ‘${var}‘… that’s call ‘string interpolation‘. Pretty simple compared to other ways I’ve had to write parameterised strings before with all kinds of place holders, parameters, and functions. I like!
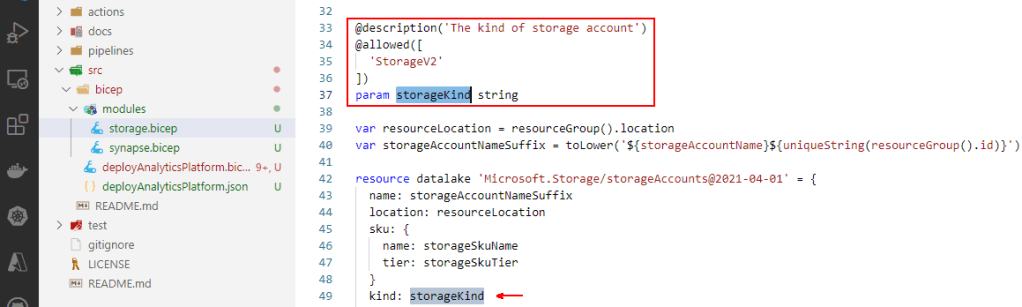
As a good practice we use parameter decorators to control parameter constraints or metadata. Things like allowed values, lengths, secure strings, etc.
Prettier.
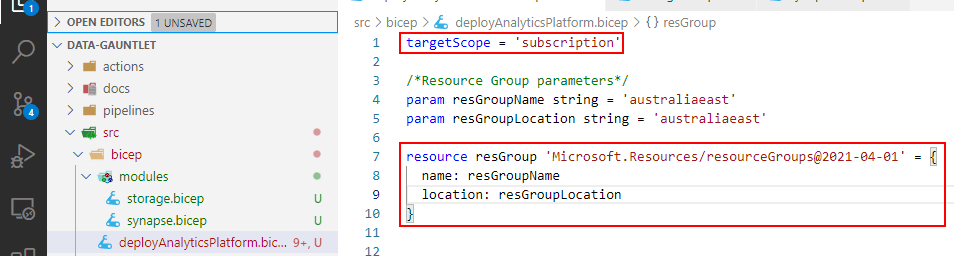
What we do next in our main deployment file is to change the scope. That way we can deploy at the subscription level which let’s us create resource groups in bicep instead of the Azure CLI which we did in the previous post.
Scoping things out 🔭
Note: It’s preferred in most cases to put all parameters/variables at the top of the file.
One other point of interest is that when we change the scope, our module to deploy resources error because they can’t be deployed at the subscription level only the resource group level. Make sense. So we need to change their scope in deployment.
Scope inception.
Polishing up the current solution with these practices was good learning. I continued with the approach across all modules and files. Then ran a few tests to make sure the resources deploy as expected.
That covers it off for this post. What I think we will do next is work on setting up a CI/CD pipeline in GitHub to build and deploy these resources into Azure.
We are using the development flow from my previous post. Not enough time? Check out the GitHub Flow.
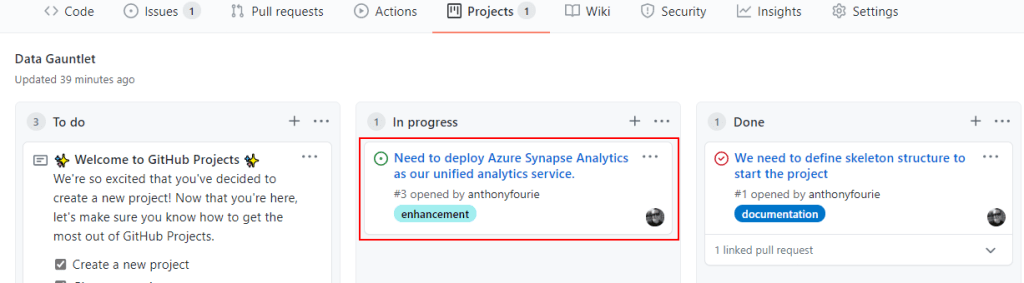
We need a starting point to build out our end-to-end analytics platform. We are going to attempt to deploy a Azure Synapse Analytics and required services with Bicep templates. This gives us two key capabilities:
Data Lake Storage to store our data
Pipelines to support orchestration and batch ingestion of data
Let’s get started. We created a new issue, updated the project board, set up our new branch in GitHub. Pulled the updates locally. Then checkout to that new branch.
Getting the hang of issues.
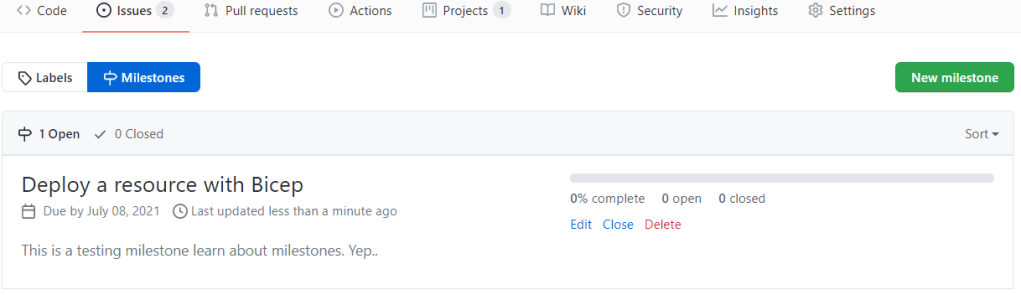
In this post though I wanted to learn about GitHub Milestones. They make it easy track a bunch of related issues. They also have convenient progress tracking built in. So I added another issue. Then made my way to the milestone page from the issues tab:
More issues.
Used the ‘New milestone’ button to create a new milestone. Gave it an name and filled in the details.
A milestone. Yep.
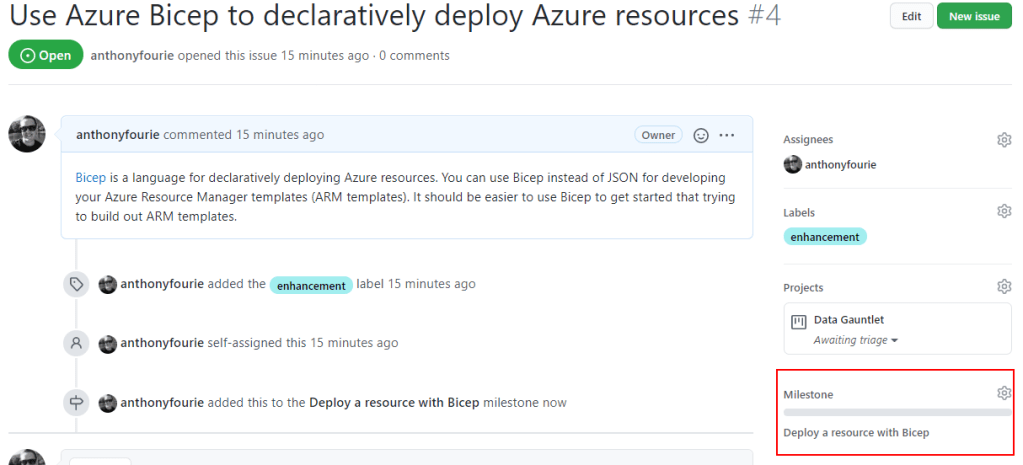
After that jump back to the issue and assign it to the milestone we just created. Notice that the milestone has a progress bar.
I will walk 500 miles.
Nice. Issues, milestones, branches, in the flow. Time to get to building things.
Building Biceps 💪
To work with Bicep files we need to install the Bicep tools (Azure CLI + Bicep install, VS Code Bicep Extension) . Once that’s done, we add our first .bicep file 🦾 to the project. Remember to check which branch you are on locally.
Flexing our first Bicep file.
Stepping back, according to the documentation, Bicep is a domain-specific language (DSL) that uses declarative syntax to deploy Azure resources. We not covering every area of Bicep here. The documentation does a good job of that. There are a few things that we am going to use in this post:
Outputs – to reuse deployed resource output variables at some point
There are a bunch of other capabilities that you can explore from loops, functions, and more. So much goodness, so little time… someday maybe.
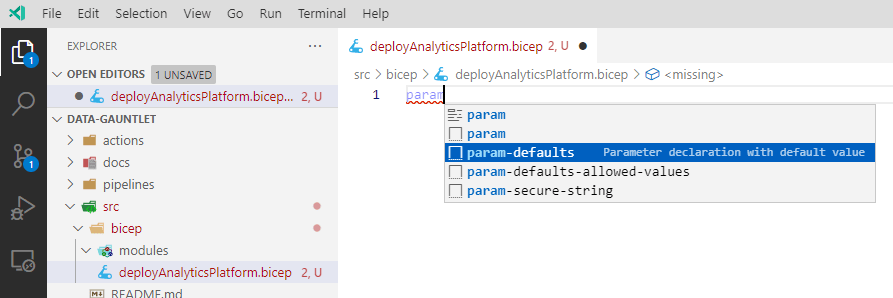
Now to start building out our resources. Let’s start with some parameters:
Intellisense integration for Bicep development.
Yes please! Intellisense for the win! I also added a comment which is being kind to my future self. Now let’s add a resource. The intellisense really helps a bunch to expedite development. We can get to the resource, the API version, and more using the Tab key. Another nice thing is using Ctrl+Space to expand more options, properties, and more:
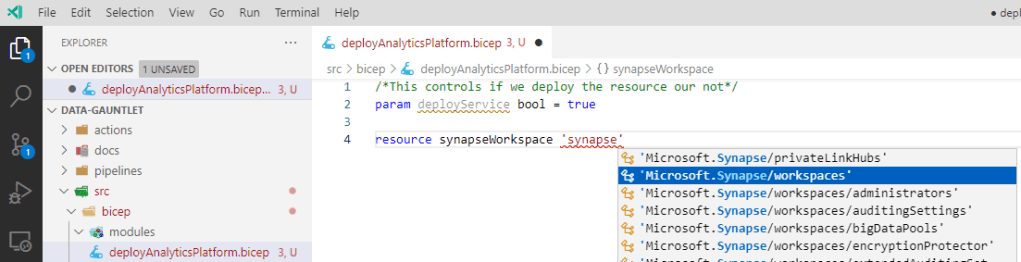
Building a Bicep resource.
We have some basic building blocks for figuring out how to create a resource. Next I expanded the declaration with more resources, parameters, comments, and properties using the template documentation and Azure-Samples.
Note: You could try create a Synapse Analytics Workspace using the portal and grab the template just before you create it as well.
Notice that you can reference the parameters in the resource declaration which helps with code reuse. I added a deployment condition to control what services get deployed. The code is in an intermediate state to showcase that I can use strings or parameters to assign values. I’ll gist show you what I did 😉:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
It’s a basic Synapse deployment. The goal is to start deploying using Bicep. We can add things like RBAC assignment for storage access, network configurations on the storage firewalls, and others.
To ship it 🚢 we can use the Azure CLI in the VS Code integrated terminal. The deployment is pretty simple. Login into your Azure subscription with the Azure CLI. Set your subscription context.
az login
az account list
az account set --subscription 'your-subscription-name-or-id'
Create a resource group in which we want to deploy the resources defined in the .bicep file. Bicep can do this which we will get to another day.
az group create --resource-group 'your-resource-group' -location 'azure-region'
Success.
Deploy the resources at a resource group level specifying the Bicep file path as our template file. Once you submit the terminal will indicate that the deployment is running. We should see a JSON summary output when it’s done similar to our resource group deployment.
az deployment group create --resource-group 'your-resource-group' --template-file 'path-to-your-bicep-file'
Deploying robots.
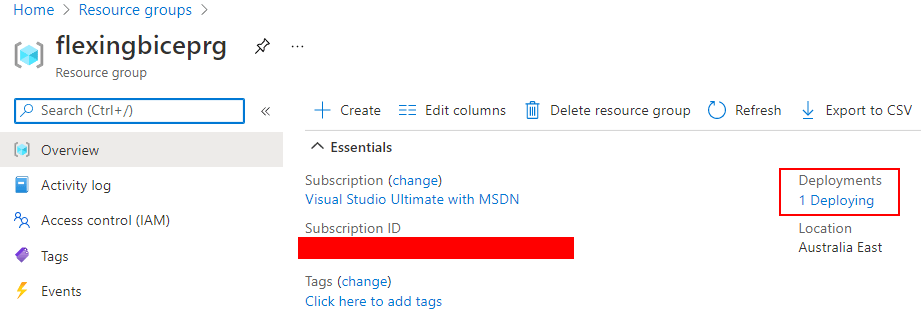
Checking the deployment in the Azure Portal is simple. Navigate to the resource group. On the ‘Overview’ page, there is a ‘Deployments’
Deployments are deploying.
If you keep following the trail, you end up at the deployment detail screen:
It’s working… It’s working! 🚀
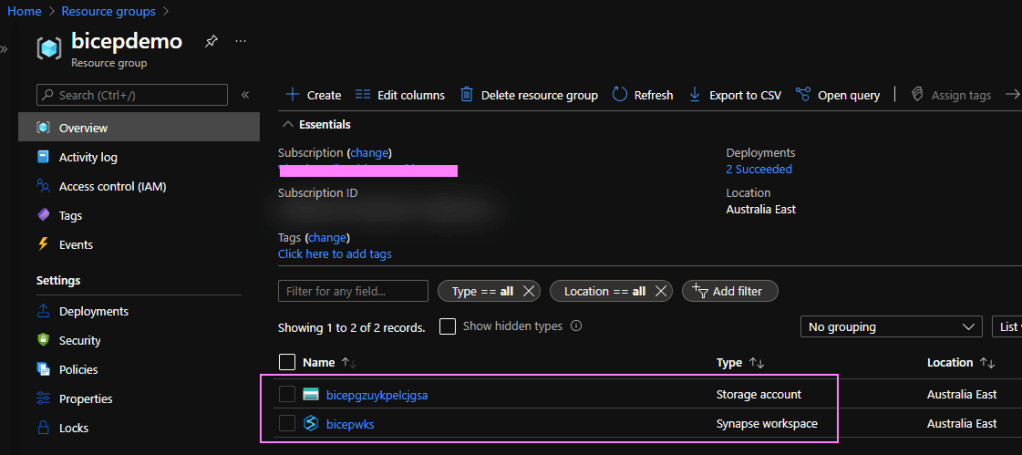
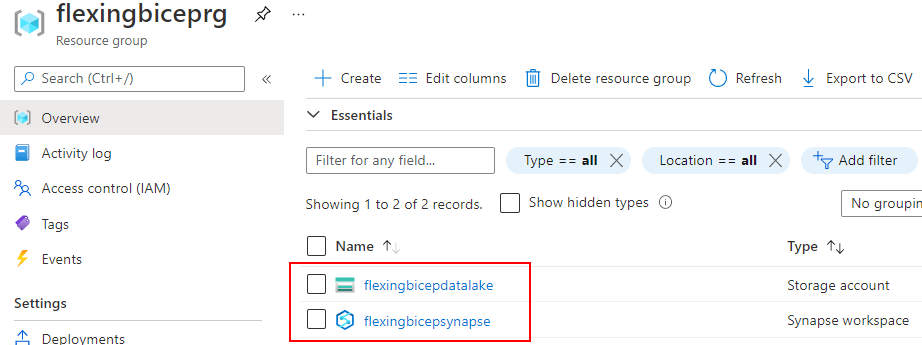
We can validate the resources are deployed in the Azure Portal:
Deployed!
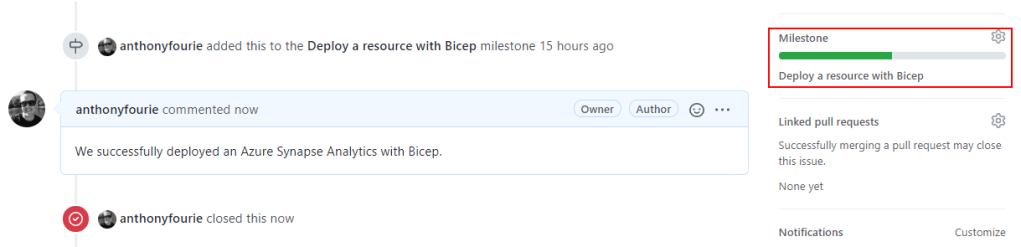
Let’s close off one of our issues and see what it does to the milestone:
Milestone achieved ✅
Awesome! To clean up, just delete the resource group 👍
az group delete --resource-group 'your-resource-group'
Interesting finds
Bicep has nice capabilities for users coming from an ARM background is that you can use the Bicep build to have it build the ARM template 😉.
az bicep build --file 'path-to-your-bicep-file'
Building ARMs from Biceps lol
If you have ARM templates, you can try out the Bicep decompile functionality to TRY (it’s not perfect, so no guarantees) convert your ARM templates to Bicep files.
az bicep decompile --file 'path-to-your-bicep-file'
Wow! Another lengthy post. Thanks for sticking around. We covered some serious ground. We learnt a bunch and kept building a foundation for our future work. Future posts we can tackle things like modules, advanced resource deployments, and deploying using GitHub actions which should be fun.
As part of my series on learning to build an End-to-End Analytics Platform project I want to start To get started here are a few things I want to get set up:
docs folder – using this to store documents related to the project.
src folder – planning to use this as the root folder for code in the repo.
test folder – planning to use this as the root folder for unit tests.
actions folder – as far as I can tell at the moment for GitHub action-related files.
GitHub Project – using this to track my work issues over time.
How did I figure out that’s how I wanted to setup the repo you ask? I took my inspiration from the atom/github: Git and GitHub integration for Atom repository. Why? Well, I am starting my learning for GitHub through a LinkedIn Learning course Learning GitHub and that was the repo showcased in intro videos.
Creating and cloning repo was easy enough using VS Code. Now I didn’t do everything in VS Code purely because I want to get a used to a few things first. So I manually grabbed the Clone URL from the GitHub repo.
Grabbing the repository URL for cloning.
All by the book so far. I opened up the Command Palette with Ctrl+Shift+P. Start typing ‘git clone’ and select the ‘Git: Clone’ operation.
Use the VS Code command palette to start Git Clone.
Pasted in the repo URL.
Paste the URL we copied earlier.
I was prompted to choose an repository location to clone the repo to. I chose to go with a folder that I can use for future repos, something like <your path>\github\<your repo>. Once that’s done, we get prompted to open up the repo.
VS Code picks up I did something.
Great! Repo has been cloned locally and the files are there. Local repository has been initialised and we are on the local main branch (see bottom left).
Enhance. We have our files.
Side note: I set a local repo user configs aligned with the user name and email to be used by git for committing to my remote GitHub repo:
Before creating feature branches I want to track my work for updating the project structure and the documentation. To do that we create a ‘Project Board‘:
Create a new project from the Projects tab.
Give it a name, description, and if you want to use a template go for it. I opted for a ‘basic kanban’ project template. As I go a long learning how all the triggers and things work this will evolve to something more sophisticated.
First look at the new spiffy project board.
It’s beginning to take shape, nice! Once that is done I need to add a work item to track my work against, to do that we create an ‘Issue‘:
Adding a new issue from the project Issues tab.
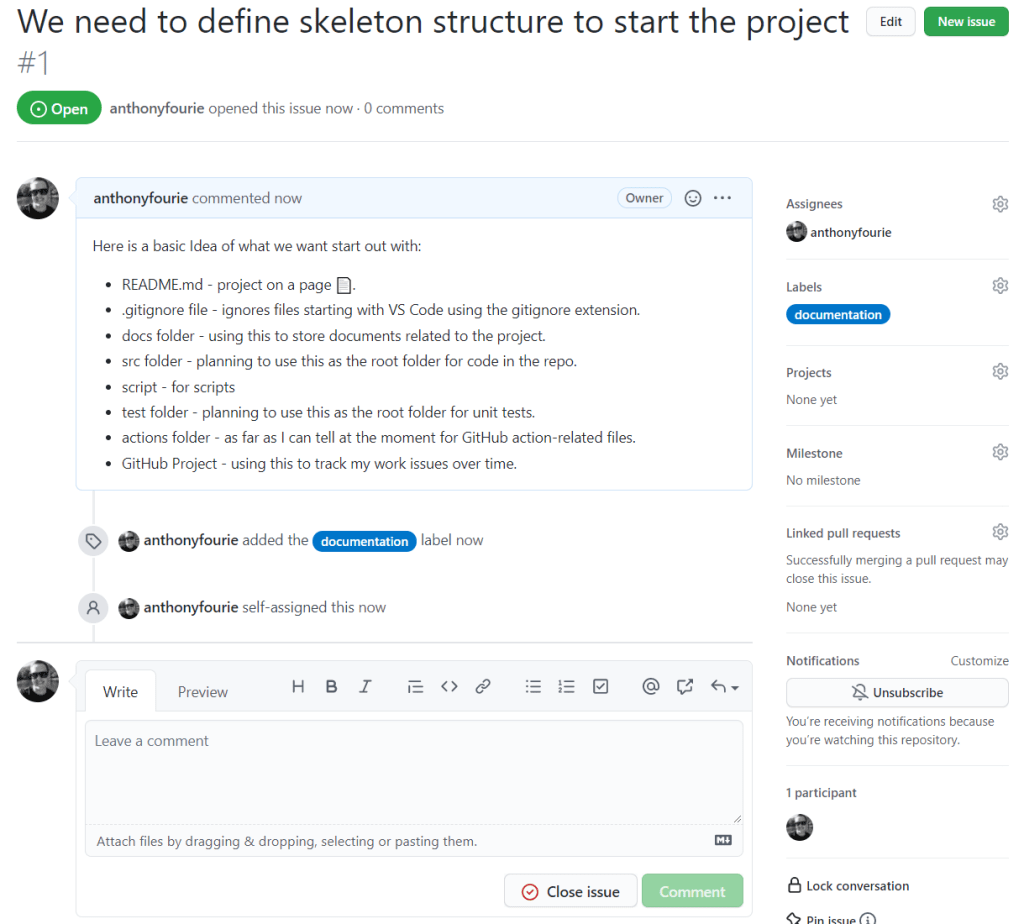
Fill it with information. Assign it to myself. Then label it with a ‘documentation’ label. Then hit the ‘Submit new issue’ button. Awesome. We now have an new issue that we can discuss, subscribe to for notifications, assign to projects, milestones, and more.
Posted new issue.
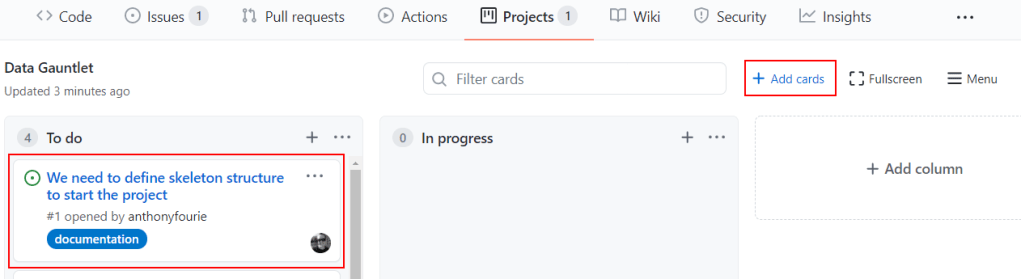
Once the issue is logged, I jumped over to the Project Board and added the ‘card’ to the ‘To Do’ swim lane. Now it automatically links up to this project.
Adding a card to the Project Board.
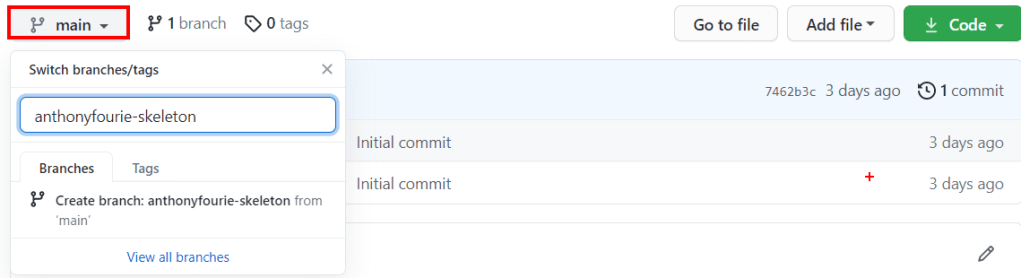
Switching over to the Code tab, we create a branch from the main branch in GitHub so that we can make our changes to that branch.
Creating a new branch from the main branch.
Once the branch is created we need to sync our local repo with a Git Pull to get the latest changes one of which is the addition of the new branch. The next point is to switch to or ‘check out’ that branch we just created. Opening up the Command Palette with Ctrl+Shift+P. Start typing ‘git checkout’ and select the ‘Git: Checkout to..’ operation. Then the feature branch you want to switch to.
Switching to the feature branch.
Next up. Make changes.
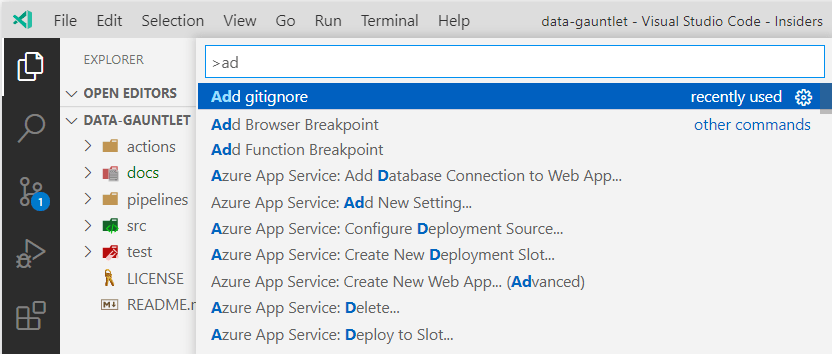
I added all the files and folders that I mentioned earlier. A noteworthy mention though was adding a .gitignore file using the gitignore extension which pulls .gitignore templates from the https://github.com/github/gitignore repository. Awesome. Didn’t know there was a repo full of .gitignore templates.
Installing the gitignore extension.
Opening up the Command Palette with Ctrl+Shift+P. Start typing ‘add gitignore’ and select the ‘Add gitignore’ operation.
Using the Command Palette to add a gitignore file.
Then just choose a template. In my case that’s ‘VisualStudioCode’.
Adding a gitignore file for Visual Studio Code.
Nice! That was pretty easy.
gitignore file added with definition.
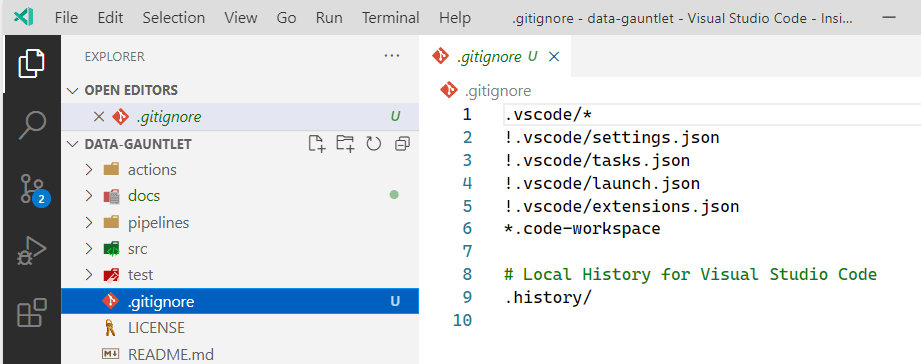
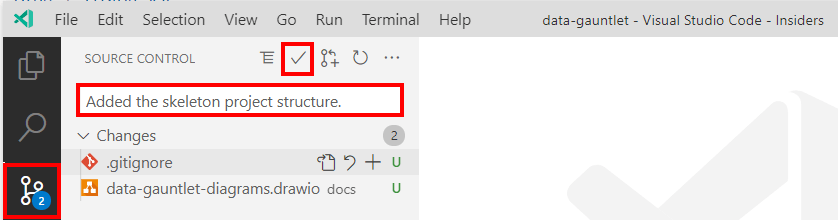
Next up push it up remote. Using the menu in the left, I switched to the Source Control view (Ctrl+Shift+G). Added a commit message. Then hit the commit button. In my case I went for the ‘stage all changes and commit them directly‘ option.
Committing the changes.
Now notice at the bottom of the screen in the status bar we can see we have a change waiting to be pushed to the remote repository in GitHub.
Awaiting the big push to the cloud.
Just click on that. Follow the prompts and VS Code will push your changes up to the remote repository. In future with branches we will follow this up with a pull request.
Once that’s done, we jump back to GitHub and we can see our branch is updated with the files we added. Next step is to finish of the flow by creating a Pull Request and merging our changes back into the main branch. To start that process we click on the ‘Compare & pull request’ button.
Starting the review and pull request process.
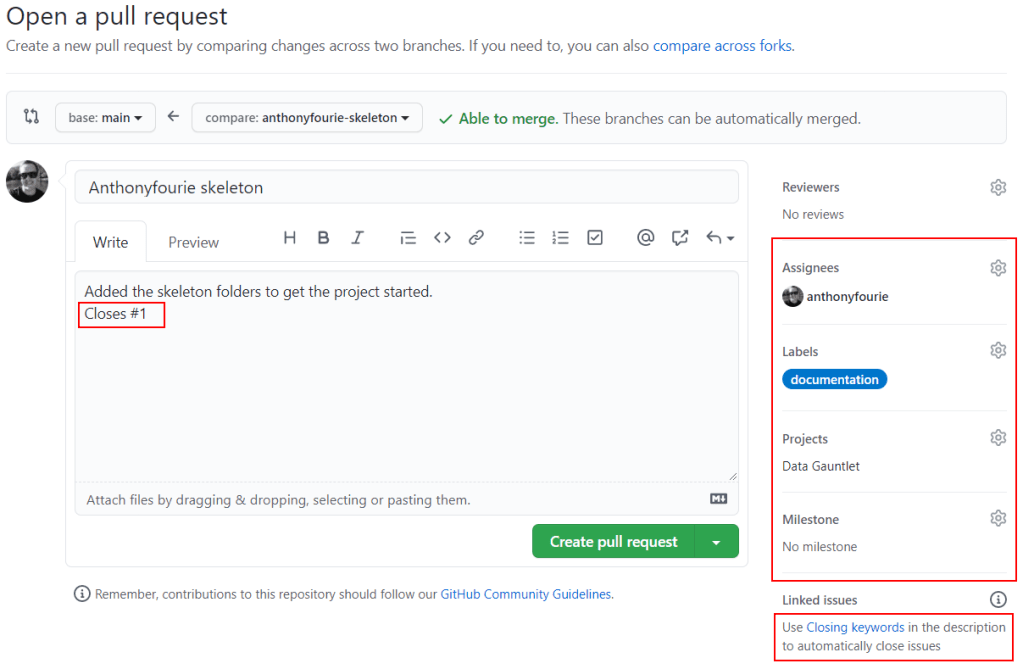
As part of the pull request we fill in as much information as we can and link any issues that we want to close automatically using keywords. Once we filled everything out and we are happy there are no conflicts, we can click on the ‘Create pull request’ button.
Filing out the pull request and closing issues.
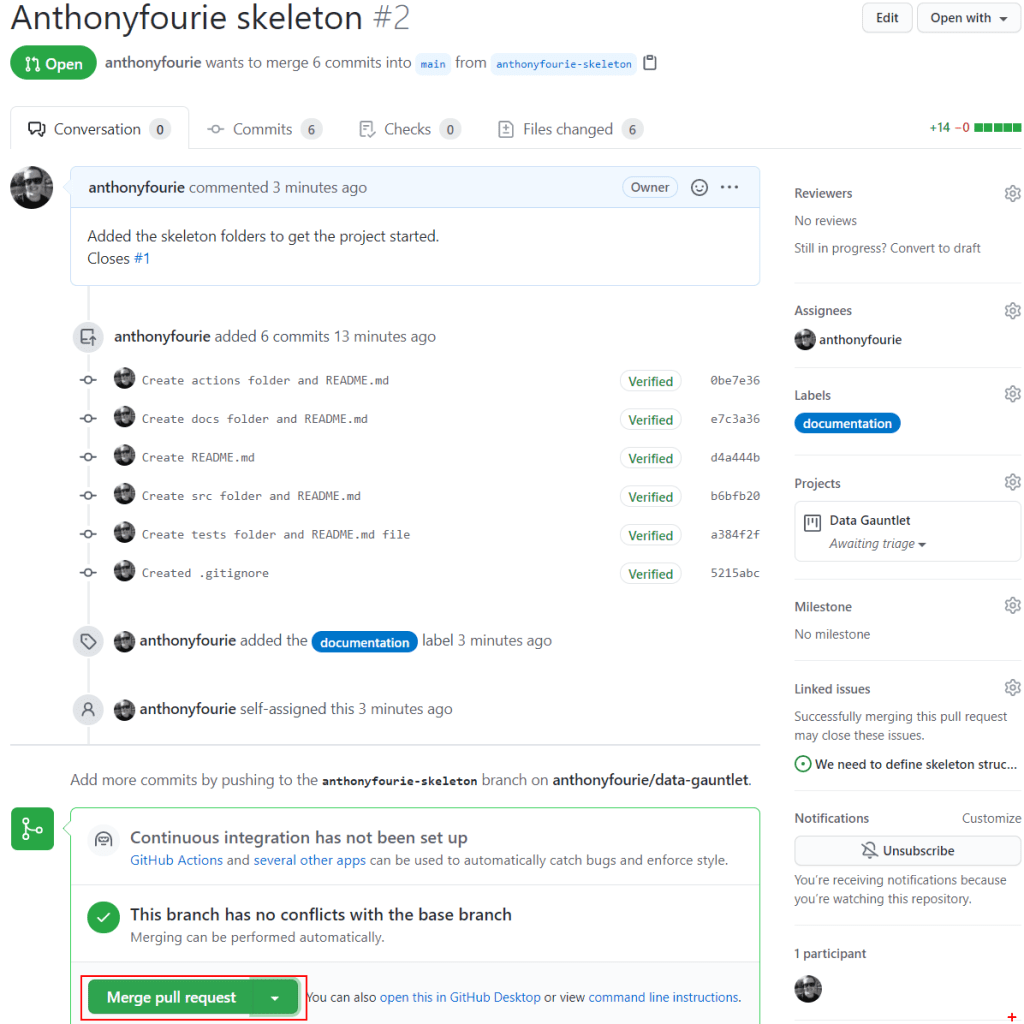
We get a valuable amount of rich history related to the work we have done here. Looking through the details I see I have no conflicts either. Let the merge begin.
Merging.
The merge is successful. In this case the work I have done on the ‘anthonyfourie-skeleton’ branch is complete. I don’t need that branch anymore so I am going to delete it.
Deleting the branch after a successful merge.
That’s it! Flipping back to the Issues tab we can see our issue has been closed. Whoop there it is!
Issue closed. Work complete.
All in all I think that was a pretty good start. Looking forward to the next post where I think I will tackle spinning up some basic infrastructure by using infrastructure as code.